nginx安装
从官方网站下载源码包(http://nginx.org/en/download.html)。
解压
1 | tar -zxvf nginx-1.*.tar.gz |
编译安装
1 | cd nginx |
可以使用
1 | ./config --help |
查看config包含的参数。
这里主要介绍几个参数:
—prefix=PATH
nginx安装部署后的根目录。默认在/usr/local/nginx目录。该目录影响其他目录的相对目录。
—sbin-path=PATH
该目录是可执行文件放置的目录。默认为\
—conf-path=PATH
配置文件目录。默认为\
—error-log-path=PATH
error日志的放置路径。默认为\
—pid-path=PATH
pid文件存放路径。默认为\
nginx的命令行控制
直接执行Nginx二进制文件
1 | /usr/local/nginx/sbin/nginx |
读取默认配置文件
指定配置文件
1 | /usr/local/nginx/sbin/nginx -c 配置文件路径 |
另行指定全局配置项
-g
1 | /usr/local/nginx/sbin/nginx -g "pid /tem/test.pid;" |
这时,pid文件将写到/tem/test.pid。-g的配置不能与nginx.conf不一致。
对于以-g启动的nginx来说,要执行其他操作,也应该包含-g参数,如
1 | /usr/local/nginx/sbin/nginx -g "pid /tem/test.pid;" -s stop |
测试配置信息是否错误
1 | /usr/local/nginx/sbin/nginx -t |
显示版本
1 | /usr/local/nginx/sbin/nginx -v |
显示编译阶段参数
1 | /usr/local/nginx/sbin/nginx -V |
快速停止服务
-s
1 | /usr/local/nginx/sbin/nginx -s stop |
-s参数是告诉Nginx向正在运行的服务发送信号。直接使用kill也是可以的。
优雅的停止服务
关闭监听端口,处理完当前所有请求。
1 | /usr/local/nginx/sbin/nginx -s quit |
等价于
1 | kill -s SIGQIT masterpid |
停止某个worker进程
1 | kill -s SIGQIT workerpid |
Nginx的配置
部署Nginx是,都是使用一个master进程来管理多个worker进程,一般worker进程数量与服务器中的CPU核心数一致。
配置demo
1 | user nobody; |
块配置
块配置项由一个块配置名和一对大括号组成。
1 | events { |
上面的events、http、server、location、upstream都是块配置项,块配置项可以嵌套。
配置项语法
基本的配置项语法为
1 | 配置项名 配置项值1 配置项值2 ... ; |
配置项值可以是数字,字符串,正则表达式,这取决于该配置项名实际需求。(这个有点像是函数名和参数的关系)。
配置项单位
指定大小时,可以使用的单位包括:
- K或者k字节(KiB)
- M或者m字节(MiB)
指定时间时,可以使用:
- ms(毫秒)
- s(秒)
- m(分钟)
- h(小时)
- d(天)
- w(周)
- M(月,30天)
- y(年,365天)
配置中使用变量
部分模块可以使用变量,如
1 | log_format main '$remote_addr [$time_local] "$request" ' |
变量前加上$。
nginx提供的基础服务
用语调试和定位问题的配置
是否以守护进程来执行
1 | daemon on|off |
是否以master/worker方式进行工作
1 | master_process on|off |
error日志设置
1 | error_log /path/file level |
当指定/path/file为/dev/null时即关闭日志。
level为日志级别。取值为debug info notice warn error crit alert emerg。从左到右等级依次升高。指定的等级时,大于等于该等级的日志都会输出。
设置特殊的调试点
1 | debug_points [stop|abort] |
nginx在关键逻辑中设置了调试点。如果设置为stop,则nginx代码运行到这些调试点就会发出SIGSTOP信号以用于调试。如果设置为abort,则会产生一个coredump文件,可以使用gdb来查看。
对指定客户端输出debug级别日志
该配置属于事件类型配置,要放在events中才有效,起值可以是IP地址或者CIDR地址,如
1 | events { |
此时,只有配置的IP才会打印debug级别日志,其他请求仍然沿用error_log中配置的日志级别。
限制coredump核心转储文件大小
1 | worker_rlimit_core size; |
指定coredump文件生成目录
1 | working_directory path; |
正常运行配置
定义环境变量
1 | env VAR|VAR=VALUE |
该配置可以让用户直接设置操作系统上的环境变量。仅是变更运行时使用的环境变量。
嵌入其他配置
1 | include /path/file |
将其他配置文件嵌入到当前配置中,参数可以是绝对路径,也可以是相对路径(相对于当前配置文件的目录)。路径可以是字符串和正则表达式。
pid文件路径
1 | pid path/file |
master进程的pid
nginx进程运行的用户及用户组
1 | user username [groupname] |
worker进程最大句柄描述符个数
1 | worker_rlimit_nofile limit; |
限制信号队列
1 | worker_rlimit_sigpending limit; |
设置每个用户发往nginx的信号队列大小,当超过该值时,该用户发送的信号将被丢弃。
性能优化配置
nginx的worker进程数
1 | worker_processes number; |
绑定nginx的worker进程到指定的CPU内核
1 | worker_cpu_affinity cpumask [cpumask, ...] |
避免多个worker进程抢占同一个cpu,设置每个进程绑定的cpu内核来加速。如
1 | worker_processes 8; |
事件类配置(都在event块中)
是否打开负载均衡锁
1 | accept_mutex [on|off] |
Accept_mutex是nginx的负载均衡锁。该锁来让各个worker进程直接负载均衡。关闭该锁可以加快TCP连接速度,但会导致负载不均衡。
lock文件路径
1 | lock_file path/file; |
存储负载均衡锁所需文件路径。
使用accept锁后未建立连接后等待时间
1 | accept_mutex_delay Nms; |
使用accept锁后,每个时刻,只能有一个worker进程能够获取accept锁。该accept不是阻塞锁,没有获取就会立即返回。如果一个worker进程尝试获取accept锁没有获得时,至少要等到accept_mutex_delay时间才能再次获取。
批量建立新连接
1 | multi_accept [on|off]; |
当事件模型通知有新连接时,尽可能地对本次调度中客户端发起的所有TCP请求都建立连接。
选择事件模型
1 | use [kqueue|rtsig|epoll|/dev/poll|select|poll|eventport] |
每个master的最大连接数
1 | worker_connections number; |
虚拟主机与请求的分发
由于IP地址限制,存在多个主机域名对应同一IP地址的情况,这时在nginx.conf中按照server_name(对应用户请求中的主机域名)并通过server块来定义虚拟机,每个server块就是一个虚拟机,它只处理与之相对应的主机域名请求。这样,一台服务器上的nginx就能够以不同方式处理访问不同主机域名的HTTP的请求了。
监听端口
1 | listen address:port [default(deprecated in 0.8.21) | default_server | [backlog=num | rcvbuf=size | sndbuf=size | accept_filter=filter | deferred | bind | ipv6only=[on|off] ssl]]; |
listen决定nginx服务监听端口。listen后可以加IP地址、端口号或者主机名。如
1 | listen 127.0.0.1:8002; |
地址后可以加其他参数。
| 参数 | 含义 |
|---|---|
| default | 将所在server块作为整个web服务的默认server块。当一个请求无法匹配配置文件中的所有主机域名时,就会选择默认虚拟主机。如果所有server都未指定,则默认选第一个。 |
| backlog=num | TCP中backlog大小。(默认-1,无限制)在TCP建立三次连接时,进程还未监听句柄,此时backlog队列将会放置这些连接。如果backlog已满,还有客户端企图建立连接,则会失败。 |
| rcvbuf=size | 设置监听句柄的SO_RCVBUF参数。 |
| sndbuf=size | 设置监听句柄的SO_SNDBUF参数。 |
| Accept_filter | 设置accept过滤,只对FreeBSD系统有用。 |
| deferred | 设置该参数时,若用户建立了TCP连接(三次握手),内核也不会对该连接调度worker进程来处理,只会在用户真正发送请求时才会分配worker进程。使用于大并发情况下。 |
| bind | 绑定当前端口/地址对,如127.0.0.1:8000。 |
| ssl | 在当前监听的端口上建立的连接必须基于SSL。 |
主机名称
1 | server_name name [...]; |
Server_name后面可以有多个主机名称,如
1 | server_name www.testweb.com download.testweb.com |
在开始处理一个HTTP请求时,nginx会取出header头中的Host,与每个server中的server_name进行比对,以决定由哪个server块来处理该请求。server_name与Host匹配优先级为:
- 最先选择完全匹配的
- 其次选择通配符在前面的,如*.testweb.com
- 再次选择通配符在后面的,如www.testweb.*
- 最后选择使用正则表达式的,如~^\.testweb.com$
Server_name后面是空字符串时,表示匹配没有这个host这个http头的请求。
server_name_hash_bucket_size
1 | server_name_hash_bucket_size size; |
为快速寻找对应server_name能力,nginx使用散列来存储server name。server_name_hash_bucket_size设置每个散列桶占用内存大小。
重定向主机名称处理
1 | server_name_in_redirect on|off; |
该配置配合server_name使用。在打开on时,表示重定向请求时会使用server_name的配置的第一个主机名代替原先请求的Host,使用off时,表示重定向时使用请求本身的Host。
location
1 | location [=|~|~*|^~|@] /uri/ {...} |
location尝试根据用户请求中的URI来匹配上面的/uri表达式,如果可以匹配,就选择location块中的请求来处理。
| 参数 | 含义 | 举例 |
|---|---|---|
= |
把URI作为字符串,与参数的uri做完全匹配 | Location = / {} |
~ |
匹配URI时是大小写敏感的 | |
~* |
忽略大小写 | |
^~ |
匹配前半部分uri即可。 | |
@ |
表示仅用于nginx服务内部请求之间的重定向,带有@的请求不直接处理用户请求。 |
最常用的是uri为正则表达式。
文件路径的定义
以root方式设置资源路径
1 | root path |
例如:
1 | location /download/ { |
对于上面的配置,如果有一个请求的URI是/download/index/test.html,那么web服务器返回服务器上/opt/web/html/download/index/test.html文件的内容。
alias方式设置资源路径
语法
1 | alias path; |
alias也是用来设置文件资源路径,与root不同点主要在于如何解读跟在location后面的uri参数,这使得alias与root以不同的方式将用户请求映射到真正的磁盘文件上。例如,如果一个请求的URI是/conf/nginx.conf,而用户实际希望访问的文件在/usr/location/nginx/conf/nginx.conf。中,如果想要使用alias来进行设置的话,可以采用如下形式:
1 | location /conf { |
如果使用root,则语句如下:
1 | location /conf { |
使用alias时,在URI向实际路径的映射过程中,已经将location后配置的/conf部分去除了,因此/conf/nginx.conf请求将根据alias path映射为path/nginx.conf。root则会根据完整的URI请求来映射,因此root会根据root path映射为path/conf/nginx.conf。
alias后面还可以添加正则表达式,例如:
1 | location ~^/test/(\w+)\.(w+)$ { |
访问首页
语法:
1 | index file |
有时,访问站点的URI为/,这一般是网页站点,这与root和alias都不同,使用nginx_http_index_module模块提供的index配置实现。index后面可以更多个文件参数,nginx会按顺序访问这些文件,例如:
1 | location / { |
根据http返回码重定向页面
语法:
1 | error_page code[code...][=|=answer-code] uri | @named_location |
对于某个请求返回错误码时,如果匹配上了error_page中设置的code,则重定向到新的URI中,例如
1 | error_page 404 /404.html |
注意,虽然重定向了URI,但返回的HTTP错误码还是原来的错误码。可以通过’=’来更改返回的错误码,例如
1 | error_page 404 = 200 /empty.html; |
也可以不指定确切的错误码,而是由重定向后时间处理的真实结果来决定,这时只要把=后面的错误码去掉即可,例如
1 | error_page 404 /empty.html; |
如果不想修改URI,只是想让请求重定向到另一个location中进行处理,那么可以设置为:
1 | location / { |
此时,出现404错误时,请求转发到反向代理http://backend服务上。
是否允许递归使用error_page
语法:
1 | recursive_error_pages [on|off]; |
try_file
语法:
1 | try_file path1[path2] uri; |
try_file后跟若果路径,如path1,path2…,最后必须要有uri参数,意义为:尝试顺序访问每一个path,如果可以有效获取,就直接向用户返回对于的文件请求,并结束,否则接着向下访问,如果所有path都找不到,则重定向到最后的uri上。例如
1 | try_file /sys/main.html $uri $uri/index/html $uri.html @other; |
示例
一个网页,要访问服务器上3个页面,为路径$path下的index.html,master.html和slave.html,其中index.html是首页,其请求的uri为/。后面两个文件是index.html返回后,请求的两个页面,请求的uri分别为/showmaster/和/showslave/。此时,nginx配置可设置为:
1 | error_log /home/work/error.log debug; |
内存及磁盘资源的分配
HTTP包体只存储在磁盘文件中
语法
1 | client_body_in_file_only on | clean | off |
当设置为非off时,用户请求的HTTP包体一律存储到磁盘文件中,即使只有0字节也会存储为文件。当配置结束时,如果设置为on,则该文件不会被删除(常用于调试),如果配置为clean,则会在请求结束,清除文件。
HTTP包体尽量写到一个内存buffer中
语法:
1 | client_body_in_single_buffer on | off |
配置on时,HTTP包体一律存储到内存buffer。如果大小超过了client_body_buffer_size值,包体依然会写入磁盘。
存储HTTP请求头部的内存大小
语法:
1 | client_header_buffer_size size; |
该配置定义了正常情况下Nginx接收用户请求中HTTP header部分(包括HTTP行和HTTP头部)分配的内存buffer大小。当HTTP header部分超过该值时,定义的buffer大小将失效。
存储超大HTTP头部的内存buffer大小
语法:
1 | lager_client_header_buffer number size; |
订阅了Nginx接收一个超大HTTP头部请求的buffer个数和每个buffer大小。如果请求行(如GET /index HTTP/1.1)大小超过上面单个大小限制时,返回Request URI too large(414)。请求中有很多header,每个header的大小也不能超过单个buffer大小,否则会返回Bad request(400)。请求行和请求头总数也不能超过buffer个数*buffer大小。
存储HTTP包体的内存buffer大小
语法:
1 | client_body_buffer_size size; |
定义了Nginx接收http请求包体的内存缓冲区大小。即HTTP包体会先接收到指定的缓存中,再决定是否写入磁盘。
HTTP包体临时存放目录
语法
1 | client_body_temp_path dir-path [level1 [level2 [level3]]] |
配置包体存放的临时目录。包体大小超过client_body_buffer_size指定大小时,会以递增的整数命名并存放到client_body_temp_path指定目录。后面的level1,level2,level3是防止一个目录文件过多,影响性能,使用level参数,可以按文件临时名再多加3层目录。
connection_pool_size
语法
1 | connection_pool_size size; |
Nginx对每一个建立的成功的TCP连接会预先分配一个内存池,这里size指定内存池初始大小,用于减少对小块内存的分配次数。过大的size导致内存资源浪费,过小的size,导致重复分配次数增加,影响性能,谨慎设置。
request_pool_size
语法
1 | request_pool_size size; |
Nginx开始处理HTTP请求时,会为每个请求都分配一个内存池。这里size指定内存池初始大小,用于减少对小块内存的分配次数。TCP连接关闭时会销毁connection_pool_size指定的内存池,HTTP请求结束会销毁request_pool_size指定的内存池,但其创建和销毁时间并不一致,因为一个TCP连接可能被复用于多个HTTP请求。
网络连接设置
读取HTTP头部超时时间
语法
1 | client_header_timeout time(s) |
客户端与服务器建立TCP连接后将开始接收HTTP头部,在这个过程中,如果在一个时间间隔内没有读取到客户端发来的字节,则认为超时,向客户端返回408(Request timed out)响应。
读取HTTP包体超时时间
语法:
1 | client_body_timeout time(s); |
与client_header_timeout类似,不过使用在读取http包体。
发送响应超时时间
语法:
1 | send_timeout time; |
Nginx向客户端发送数据包,客户端一直没有接收数据包,超过超时响应时间后,Nginx关闭连接。
还有很多网络连接配置,看书。
client_body_in_file_only
此指令禁用NGINX缓冲区并将请求体存储在临时文件中。 文件包含纯文本数据。 该指令在NGINX配置的http,server和location区块使用。
1 | client_body_in_file_only off|on|clean |
不同值含义如下:
- off 该值将禁用文件写入
- clean:请求body将被写入文件。 该文件将在处理请求后删除。
- on:请求正文将被写入文件。 处理请求后,将不会删除该文件。
client_body_in_single_buffer
该指令设置NGINX将完整的请求主体存储在单个缓冲区中。 默认情况下,指令值为off。如果启用,它将优化读取$request_body变量时涉及的I/O操作。
长连接
http为了避免每次都需要进行连接的三次握手和四次挥手,支持连接的复用,报错连接为长连接。nginx也支持该功能。对应的配置包括。
keepalive_requests
长连接最多接收的请求数量。语法为:
1 | Syntax: keepalive_requests number; |
keepalive_timeout
对于保持长连接的请求来说,如果指定事件未收到请求,则关闭连接。配置如下:
1 | Syntax: keepalive_timeout timeout [header_timeout]; |
如果配置的事件为0,则表示不支持长连接。可选的第二个参数在响应的header域中设置一个值“Keep-Alive: timeout=time”。这两个参数可以不一样。
除了长连接以外,还有一个特性为pipeline。
在http1.1中,引入了一种新的特性,即pipeline。那么什么是pipeline呢?pipeline其实就是流水线作业,它可以看作为keepalive的一种升华,因为pipeline也是基于长连接的,目的就是利用一个连接做多次请求。如果客户端要提交多个请求,对于keepalive来说,那么第二个请求,必须要等到第一个请求的响应接收完全后,才能发起,这和TCP的停止等待协议是一样的,得到两个响应的时间至少为2RTT。而对pipeline来说,客户端不必等到第一个请求处理完后,就可以马上发起第二个请求。得到两个响应的时间可能能够达到1RTT。nginx是直接支持pipeline的,但是,nginx对pipeline中的多个请求的处理却不是并行的,依然是一个请求接一个请求的处理,只是在处理第一个请求的时候,客户端就可以发起第二个请求。这样,nginx利用pipeline减少了处理完一个请求后,等待第二个请求的请求头数据的时间。其实nginx的做法很简单,前面说到,nginx在读取数据时,会将读取的数据放到一个buffer里面,所以,如果nginx在处理完前一个请求后,如果发现buffer里面还有数据,就认为剩下的数据是下一个请求的开始,然后就接下来处理下一个请求,否则就设置keepalive。
tcp_nopush/tcp_nodelay
对于tcp连接来说,缓存中数据发送方式会对传输存在一定的影响。
如果是缓存中有数据就立即发出,将导致负载过高的问题。例如可能传输的数据只有一个字节,但tcp头本身就有40字节长度,效率过低。因此当前tcp默认传输方式是使用Nagle算法,TCP堆栈实现了等待数据 0.2秒钟,因此操作后它不会发送一个数据包,而是将这段时间内的数据打成一个大的包。
但等待0.2秒不一定适合所有场景,因此有了tcp_nopush和tcp_nodelay方式,这些都是套接字属性,通过setsockopt系统调用设置套接字属性即可。
在 nginx 中,tcp_nopush 配置和 tcp_nodelay “互斥”。它可以配置一次发送数据的包大小。也就是说,它不是按时间累计 0.2 秒后发送包,而是当包累计到一定大小后就发送。在 nginx 中,tcp_nopush 必须和 sendfile 搭配使用。
tcp_nodelay表示不使用等待,立即发送。
默认配置为:
1 | tcp_nopush : on; |
配置块在http、server、location中。
延迟关闭(lingering_close)
lingering_close,字面意思就是延迟关闭,也就是说,当nginx要关闭连接时,并非立即关闭连接,而是先关闭tcp连接的写,再等待一段时间后再关掉连接的读。为什么要这样呢?我们先来看看这样一个场景。nginx在接收客户端的请求时,可能由于客户端或服务端出错了,要立即响应错误信息给客户端,而nginx在响应错误信息后,大分部情况下是需要关闭当前连接。nginx执行完write()系统调用把错误信息发送给客户端,write()系统调用返回成功并不表示数据已经发送到客户端,有可能还在tcp连接的write buffer里。接着如果直接执行close()系统调用关闭tcp连接,内核会首先检查tcp的read buffer里有没有客户端发送过来的数据留在内核态没有被用户态进程读取,如果有则发送给客户端RST报文来关闭tcp连接丢弃write buffer里的数据,如果没有则等待write buffer里的数据发送完毕,然后再经过正常的4次分手报文断开连接。所以,当在某些场景下出现tcp write buffer里的数据在write()系统调用之后到close()系统调用执行之前没有发送完毕,且tcp read buffer里面还有数据没有读,close()系统调用会导致客户端收到RST报文且不会拿到服务端发送过来的错误信息数据。那客户端肯定会想,这服务器好霸道,动不动就reset我的连接,连个错误信息都没有。
在上面这个场景中,我们可以看到,关键点是服务端给客户端发送了RST包,导致自己发送的数据在客户端忽略掉了。所以,解决问题的重点是,让服务端别发RST包。再想想,我们发送RST是因为我们关掉了连接,关掉连接是因为我们不想再处理此连接了,也不会有任何数据产生了。对于全双工的TCP连接来说,我们只需要关掉写就行了,读可以继续进行,我们只需要丢掉读到的任何数据就行了,这样的话,当我们关掉连接后,客户端再发过来的数据,就不会再收到RST了。当然最终我们还是需要关掉这个读端的,所以我们会设置一个超时时间,在这个时间过后,就关掉读,客户端再发送数据来就不管了,作为服务端我会认为,都这么长时间了,发给你的错误信息也应该读到了,再慢就不关我事了,要怪就怪你RP不好了。当然,正常的客户端,在读取到数据后,会关掉连接,此时服务端就会在超时时间内关掉读端。这些正是lingering_close所做的事情。协议栈提供 SO_LINGER 这个选项,它的一种配置情况就是来处理lingering_close的情况的,不过nginx是自己实现的lingering_close。lingering_close存在的意义就是来读取剩下的客户端发来的数据,所以nginx会有一个读超时时间,通过lingering_timeout选项来设置,如果在lingering_timeout时间内还没有收到数据,则直接关掉连接。nginx还支持设置一个总的读取时间,通过lingering_time来设置,这个时间也就是nginx在关闭写之后,保留socket的时间,客户端需要在这个时间内发送完所有的数据,否则nginx在这个时间过后,会直接关掉连接。
lingering_close
设置是否需要延迟关闭。语法如下:
1 | Syntax: lingering_close off | on | always; |
默认值“on”指示 nginx 在完全关闭连接之前等待并处理来自客户端的额外数据,但前提是启发式表明客户端可能正在发送更多数据。
值“always”将导致 nginx 无条件等待和处理额外的客户端数据。
值“off”告诉nginx永远不要等待更多数据并立即关闭连接。 这种行为违反了协议,不应在正常情况下使用。
lingering_time
设置总的延迟时间。当 lingering_close 生效时,该指令指定 nginx 处理(读取和忽略)来自客户端的附加数据的最长时间。 之后,即使会有更多数据,连接也会关闭。语法如下:
1 | Syntax: lingering_time time; |
lingering_timeout
当 lingering_close 生效时,该指令指定更多客户端数据到达的最大等待时间。 如果在此期间未收到数据,则关闭连接。 否则,数据被读取并忽略,nginx再次开始等待更多数据。 重复“等待-读取-忽略”循环,但不会超过 lingering_time 指令指定的时间。
语法如下:
1 | Syntax: lingering_timeout time; |
加速close
在某个请求超时时,nginx会主动关闭该请求,这时会主动调用close函数来关闭套接字,但主动关闭套接字会导致套接字处于TIME_WAIT状态,这将导致大量的超时连接无法被立即释放,造成大量浪费。
tcp通过了SO_LINGER选项来设置关闭方式。其中参数为linger结构:
1 | struct linger |
当l_onoff为正数,l_linger为0时,会立即在执行close时,立即向客户端发送RST报文,立即关闭连接,并释放此套接字占用的所有内存。
nginx中使用reset_timedout_connection配置来支持该功能:
1 | Syntax: reset_timedout_connection on | off; |
当配置为on时,会快速关闭。
Nginx常用数据结构
ngx_buf_t
1 | typedef struct ngx_buf_s ngx_buf_t; |
ngx_buf_t为缓存区结构。
ngx_chain_s
该结构为配合ngx_buf_t使用的链表,定义如下:
1 | struct ngx_chain_s { |
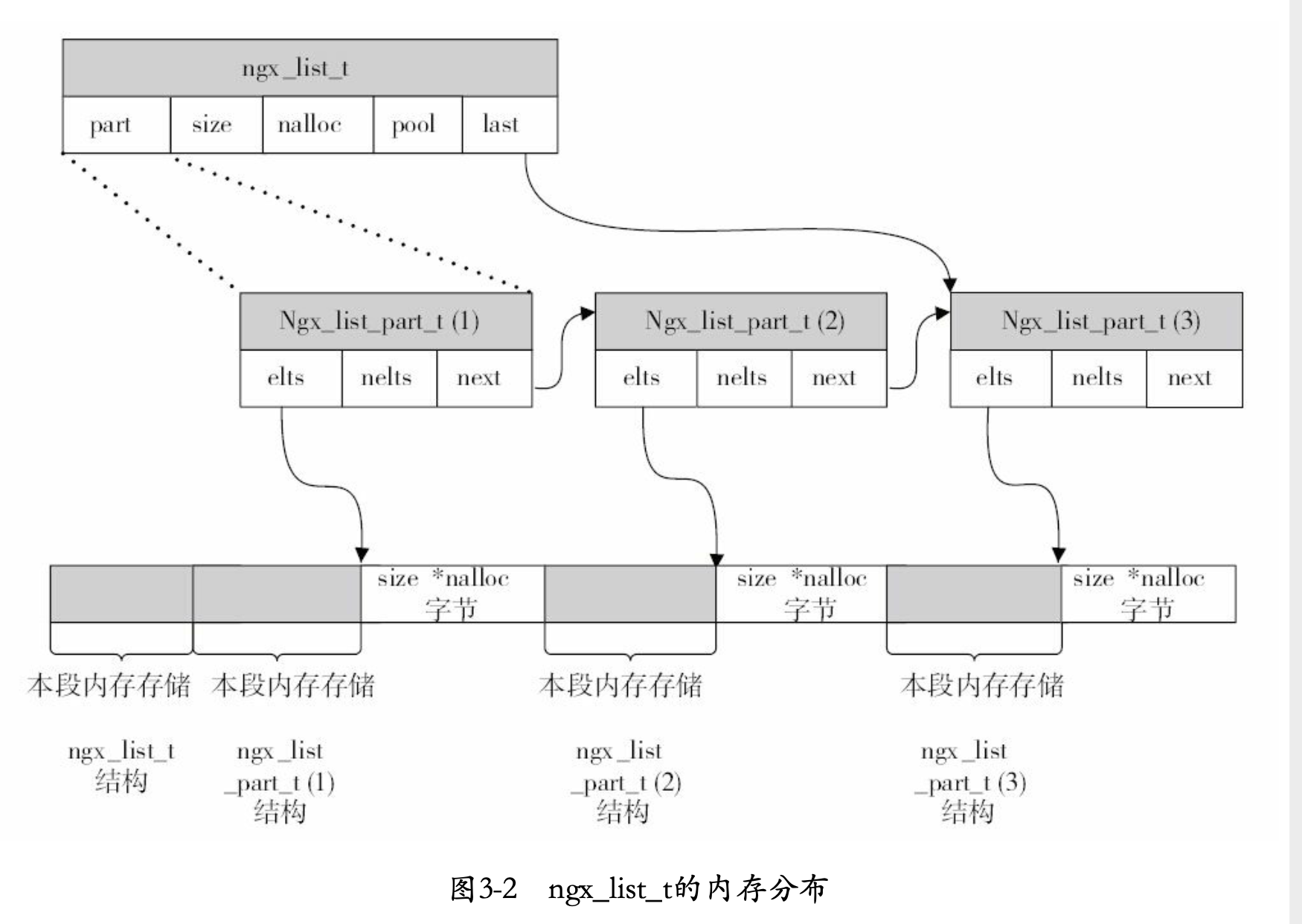
ngx_list_t
ngx_list_t为nginx封装的链表容器,其定义如下:
1 | typedef struct ngx_list_part_s ngx_list_part_t; |
ngx_list_t描述整个链表,ngx_list_part_s,描述每个链表的元素。每个链表的元素ngx_list_part_s是一个数组,拥有连续的内存,依赖ngx_list_t的size和nalloc来表示数组容量,又依赖每个ngx_list_part_s成员的nelts来表示已经使用的容量。
初始化链表ngx_list_init
1 | static ngx_inline ngx_int_t |
创建list ngx_list_create
1 | ngx_list_t * |
添加数据ngx_list_push
该方法返回添加元素对应的地址,返回地址后由调用方对地址赋值。
1 | void * |
ngx_table_elt_t
1 | typedef struct { |
ngx_table_elt_t是一个Key/Value对。主要使用于解析http头部。
散列表(ngx_hash_t)
存储散列表的类有如下三个相关结构:
1 | // hash基础数据类 |
散列表构建
构建hash表使用函数ngx_hash_init:
1 |
|
散列表查找
1 | void * |
管理散列表(ngx_hash_keys_arrays_t)
nginx为了让大家方便的构造hash表,提供给了此辅助类型,如下:
1 | typedef struct { |
构建ngx_hash_keys_arrays_t
使用ngx_hash_keys_array_init构建该结构:
1 | ngx_int_t |
添加元素
使用如下函数增加元素:
1 | /* flag取值有三种:NGX_HASH_WILDCARD_KEY表示需要处理通配符。 NGX_HASH_READONLY_KEY表示不能对关键字做变更,即不能通过全小写关键字来获取散列码,其他值:即不处理通配符,又允许把关键字全小写获取散列码*/ |
对于构建好的通配符数组,不能直接调用ngx_hash_wildcard_init来构建包含通配符的散列表,而是要先对数组进行排序,这就是为什么要在字节后面添加\0的作用,用于判断字符串结尾。排序时,.被认为是最低顺序的字节,即:example.com小于(排在前面)example1.com。
带有通配符的散列表(ngx_hash_wildcard_t)
1 | typedef struct { |
nginx支持的带通配符的散列表,仅支持在起始或末尾带有散列表,即如下:
1 | www.baidu.* |
构建带有通配符的散列表
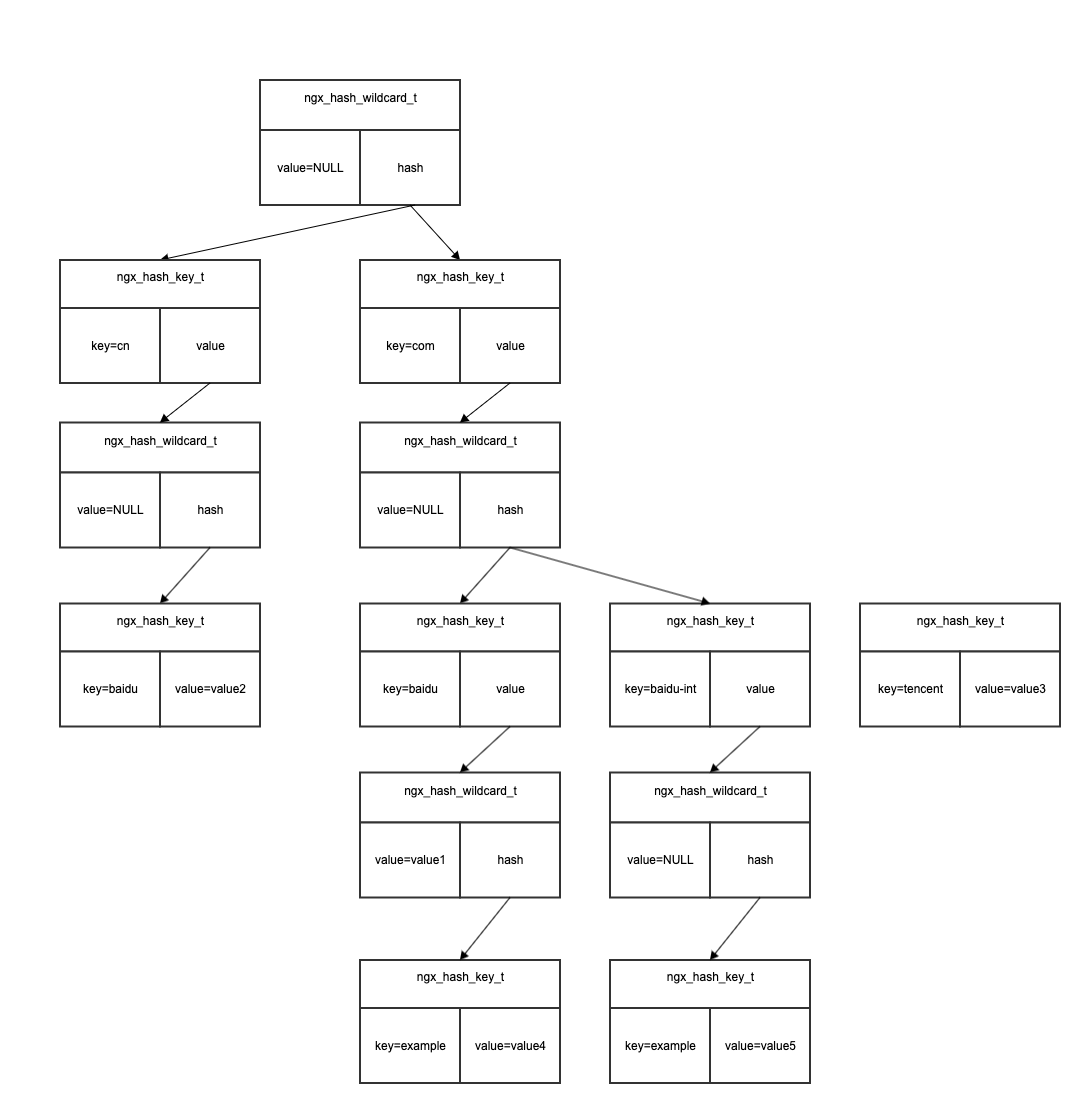
ngx_hash_wildcard_init函数用来构建带有通配符的散列表。这里需要注意,不论是构建前置为通配符还是后置为通配符,其中的参数,即ngx_hash_key_t列表,均是z已被排序好的,即key均被排序完成,这时为了方便后续的构建。对于含有通配符的hash表来说,其是一个层级结构。例如对于如下两个key:
1 | www.baidu.com |
则构建的hash表为:
1 | 第一级 第二级 第三极 |
查找时也是同样的逻辑,先按照.划分块,再一层一层查找。这也是为啥要将前置的通配符反转,变更成类似于后置的结构。
具体逻辑如下:
1 | ngx_int_t |
对于如下数据:
1 | *.baidu.com value1 |
首先被转换并排序为:
1 | cn.baidu. value2 |
构建多层hash表如下:
查找后缀通配符
使用ngx_hash_find_wc_tail在后缀通配符中查找:
1 | void * |
查找前缀通配符
1 | void * |
ngx_queue_t双向循环链表
数据结构
1 | typedef struct ngx_queue_s ngx_queue_t; |
ngx_queue_s维持了双向链表,忽略了其实际元素的内容,不负责链表元素的内存分配。要想使用双向链表,则要求我们定义的类能够通过指针转换为ngx_queue_s,因此其必须包含*prev和*next。此时可以直接通过指针来进行转换。例如:
1 | struct my_test { |
注意双向循环链表存在一个维护双向链表结构的节点,该节点不存储数据,只是作为维护结构的节点。后续参数中h,表示维护链表的节点,参数为q表示存储数据的节点。
初始化双向循环链表:ngx_queue_init(q)
1 | #define ngx_queue_init(q) \ |
q为链表容器结构ngx_queue_s。
判空:ngx_queue_empty(h)
1 | #define ngx_queue_empty(h) \ |
由于是循环链表,因此只需要判断任意一个链表元素的前驱是否为自身即可。这里使用的是维护结构的节点。
在头部插入元素:ngx_queue_insert_head(h,x)
在维护链表的节点后增加一个元素,即为在链表头插入元素。:
1 | #define ngx_queue_insert_head(h, x) \ |
在尾部插入节点:ngx_queue_insert_tail(h,x)
在维护链表的节点前插入一个元素,即为在链表尾部插入元素(双向的作用)
1 | #define ngx_queue_insert_tail(h, x) \ |
获取列表第一个元素:ngx_queue_head(h)
维护链表节点的后一个元素即为首尾元素:
1 | #define ngx_queue_head(h) \ |
获取列表中最后一个元素:ngx_queue_last(h)
维护链表节点的前一个元素即为首尾元素:
1 | #define ngx_queue_last(h) \ |
返回链表容器结构体指针:ngx_queue_sentinel(h)
1 |
|
常在循环中判断终止。
获取当前元素的下一个元素:ngx_queue_next(q)
1 | #define ngx_queue_next(q) \ |
获取当前元素的上一个元素:ngx_queue_prev(q)
1 | #define ngx_queue_prev(q) \ |
移出元素:ngx_queue_remove(x)
1 | #define ngx_queue_remove(x) \ |
拆分链表:ngx_queue_split(h, q, n)
h为维护链表节点,q为其中一个元素,该方法将链表切割成两部分,通过q进行切割成两个链表h和n,前半部分h由原链表的前半部分构成(不包含q),n链表由原链表的后半部分组成,q为其首元素。
1 | #define ngx_queue_split(h, q, n) \ |
合并链表:ngx_queue_add(h, n)
将n链表添加到h链表的末尾。
1 | #define ngx_queue_add(h, n) \ |
返回元素对应的地址:ngx_queue_data(q, type, link)
对应能够转换为ngx_queue_t的元素,使用该方法,通过元素内容,获取ngx_queue_t的起始地址:
1 | #define ngx_queue_data(q, type, link) \ |
在指定元素后插入内容:ngx_queue_insert_after(h, x)
与ngx_queue_insert_head类似,不过一个是维护链表的节点,一个是存储数据的节点:
1 | #define ngx_queue_insert_after ngx_queue_insert_head |
返回链表中心元素:ngx_queue_middle(ngx_queue_t *queue)
其处理方式为,分配两个指针middle和next,都从头开始遍历链表,让next一次走两步,middle一个走一步,当next走到终点时,milddle就是中间节点。具体逻辑如下:
1 | ngx_queue_t * |
对链表排序:ngx_queue_sort
按照指定排序方式对链表排序:采用稳定的插入排序算法
1 | void |
红黑树ngx_rbtree_node_t
关于红黑树具体介绍及代码实现可以参考如下文档:红黑树。
数据结构
1 | typedef ngx_uint_t ngx_rbtree_key_t; |
对应节点来说,与之前的结构类似,存储数据要依托于ngx_rbtree_node_s结构,因此可以自定义节点元素,但是必须包含ngx_rbtree_node_s结构,以使得方便结构体强制转换为ngx_rbtree_node_s结构。例如:
1 | typedef struct { |
红黑树节点提供的方法
设置节点颜色
1 | #define ngx_rbt_red(node) ((node)->color = 1) |
判断节点颜色
1 | #define ngx_rbt_is_red(node) ((node)->color) |
拷贝节点颜色
1 | #define ngx_rbt_copy_color(n1, n2) (n1->color = n2->color) |
将n1节点变更为与n2一样。
初始化哨兵节点
1 | #define ngx_rbtree_sentinel_init(node) ngx_rbt_black(node) |
哨兵节点为黑色节点,因此设置节点为黑色即可。
查找子树中最小节点
1 | static ngx_inline ngx_rbtree_node_t * |
以key为关键字,查找最小的一个节点。
红黑树容器提供的方法
初始化红黑树ngx_rbtree_init
1 | #define ngx_rbtree_init(tree, s, i) \ |
参数tree是红黑树容器指针,s是哨兵节点指针,i为ngx_rbtree_insert_pt类型的节点添加方法。
寻找下一个元素ngx_rbtree_next
1 | // 在tree容器中,找到第一个比node大的元素 |
旋转节点
1 | // 左旋 |
关于节点旋转,这里不详细介绍,具体参考文档:红黑树。
添加节点ngx_rbtree_insert
向红黑树容器中增加节点:
1 | void |
nginx提供了三种ngx_rbtree_insert_pt方法来增加元素,后续会详细介绍,关于如果重新平衡二叉树,也参考文档即可:红黑树。
删除元素
1 | void |
删除元素这里也不过多介绍,阅读文档即可。
架构提供的三个ngx_rbtree_insert_pt增加节点函数。
ngx_rbtree_insert_value
使用场景:向红黑树中增加数据节点,每个数据节点的关键字都是唯一的,不存在同一个关键字有多个节点的情况。
逻辑如下:
1 | void |
ngx_rbtree_insert_timer_value
该函数向红黑树添加数据节点,每个节点的关键字表示时间或者时间差。因此其中的key可能为负数。这是并不关心是否有重复的key。其逻辑如下:
1 | void |
与ngx_rbtree_insert_value逻辑一致,只是做了一个ngx_rbtree_key_int_t的强制类型转换,支持负数。
ngx_str_rbtree_insert_value
向红黑树中增加节点,每个数据节点的关键字可以不唯一,但是以字符串作为唯一标识,存放在ngx_str_node_t的str中。ngx_str_node_t定义如下:
1 | typedef struct { |
对应的插入方法为:
1 | void |
与前两个类似,但是增加了对str的比较。
Nginx特殊技巧
ngx_align 值对齐宏
ngx_align 为nginx中的一个值对齐宏。主要在需要内存申请的地方使用,为了减少在不同的 cache line 中内存而生。
1 | // d 为需要对齐的 |
原理简单,利用 ~(a - 1) 的低位全为 0。在与 ~(a - 1) 做 & 操作时,低位的1被丢弃,就得到了a倍数的值(对齐)。
如果使用原始值直接与 ~(a - 1) 做 & 操作,那么得到的对齐值是会小于等于原始值的,这样会造成内存重叠,而期望的对齐值是一个大于等于原始值的,所以需要加上一个数来补上至对齐值这中间的差,这个数为 (a - 1) ,选择这个数的原因是 (a - 1) & ~(a - 1) 的结果为0。
该操作含义为:取大于d且为a整数倍的第一个数。
ngx_align_ptr内存对其
1 |
|
这里和上面都存储对其类似,a一般是cache line大小。对其后,指针指向cache line的整数倍的地方,加快读取速度。具体参考下面文章。
https://oopschen.github.io/posts/2013/cpu-cacheline/
指针最后两位一定是0
字节对齐和系统有关,也和编译器有关,具体到底是几字节对齐和本问题关系不大。主要是因为无论如何对齐,都是字节对齐,而不是bit对齐。也就是说指针的起始存放地址只可能是8的倍数,比如0x00,0x08,0x10,转换成二进制后三位永远是0。不可能出现0x02到0x22作为一个四字节的指针。
ps1:有些资料中将之描述为指针的后2位永远是0,猜想是汇编语言中好像有的语句可以把4bit看作一个基本的操作单位,所以只能保证指针的后2位永远是0。
ps2:是否可以申请一个数组,然后对其中的位进行操作,使之出现一个类似0x02到0x22作为一个四字节指针的情况,将这个畸形的指针传入指针操作API中会导致什么后果,这个问题还有待考证。
出处:https://www.zhihu.com/question/40636241/answer/311889614
内联汇编
内联汇编语言可以直接操作硬件。可以用来在nginx源码中实现对整数的原子操作。
使用GCC编译器在C语言中嵌入汇编语言的方式是使用__asm__关键字,语法如下:
1 | __asm__ volatile ( 汇编语句部分 |
加入volatile关键字用于限制GCC编译器对这段代码做优化。
内联汇编语言包含四部分:
汇编语句部分
引号中所包含的汇编语句可以直接用占位符%来引用C语言中的变量(最多10个,%0-%9)。
输出部分
将寄存器中的值设置到C语言的变量中
输入部分
将C语言中的变量设置到寄存器中。
破坏描述部分
通知编译器使用了哪些寄存器、内存。
以如下语句举例:
1 | static ngx_inline ngx_atomic_uint_t |
先看输入部分:”m” (*lock)表示lock变量是在内存中,操作\lock直接通过内存(不使用寄存器处理),而”a” (old)表示把old变量写入eax寄存器中,”r” (set)表示把set变量写入通用寄存器中。这些都是为cmpxchgl做准备。
再来看汇编语句部分:”lock”表示在多核架构上首先锁住总线。
cmpxchgl语句含义为如下代码表示:
1 | /* |
即判断寄存器中的值是否等于[m],如果相等,则设置[m]为r,并且设置sf为1。否则,设置zf为0,并且设置寄存器中值为[m]。
在语句cmpxchgl %3, %1;中,寄存器变量为old。%3表示set,%1表示loct。先比较\lock是否等于old,如果相等设置*lock为set。并进行zf设置。
“sete %0;”表示设置zf值到寄存器变量中。
返回部分”=a” (res)将寄存器中值写入res变量中,返回。
Nginx架构及启动流程
Nginx的架构设计
优秀的模块化设计
高度模块化的设计是Nginx的架构基础。在nginx中,除了少量的核心代码,其他一切皆为模块。其具有如下特点:
高度抽象的模块接口
所有模块都遵循同样的ngx_module_t接口设计规范,减少了系统变数。
模块接口非常简单,具有高度灵活性
模块的基本接口nginx_module_t足够简单,只设计模块的初始化、退出以及对配置项的处理,同时带来了足够的灵活性。
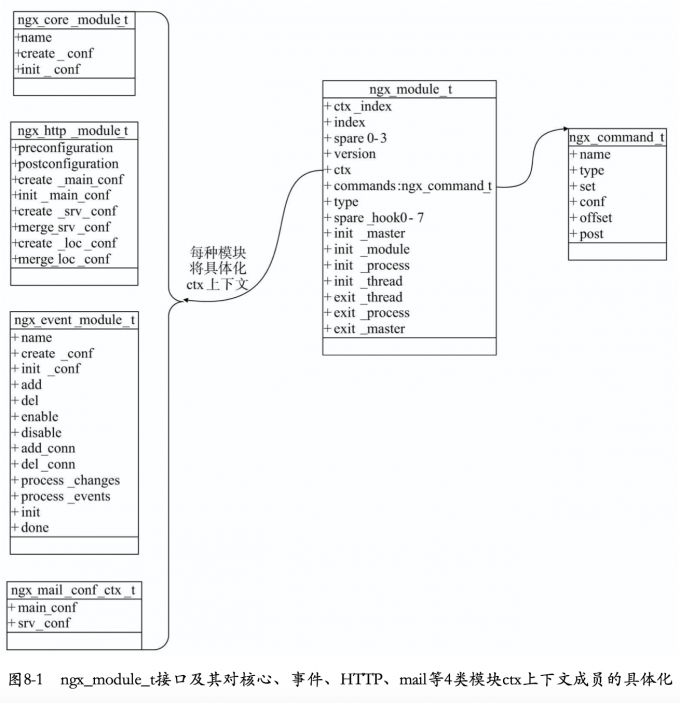
如图所示,nginx_module_t结构体作为所有模块的通用接口,其只定义了
init_master init_module init_process init_thread exit_thread exit_process exit_master这七个回调方法,他们负责模块的初始化与退出,同时权限非常高,可以处理核心结构体nginx_cycle_t。
nginx_module_t类
nginx_module_t结构如下:
1 | struct ngx_module_s { |
ctx是void指针,可以指向任何数据,这改模块提供了极大的灵活性。
配置模块的设计
ngx_module_t接口中type类型指名了nginx在设计模块时定义模块类型,允许专注于不同领域的模块按照类型来区别。配置类型模块是唯一一个只有一个模块的模块类型。配置模块的类型叫做NGX_CONF_MODULE,其仅有的模块为ngx_conf_module,其为底层模块,指导所有模块以配置项为核心来提供功能。
核心模块的简单化
多层次,多类别的模块设计
所以模块间是分层次、分类别的,官方Nginx共用5大类型模块:核心模块、配置模块、时间模块、HTTP模块、mail模块。虽然都具备相同的ngx_module_t接口,但在请求处理中的层级并不相同。
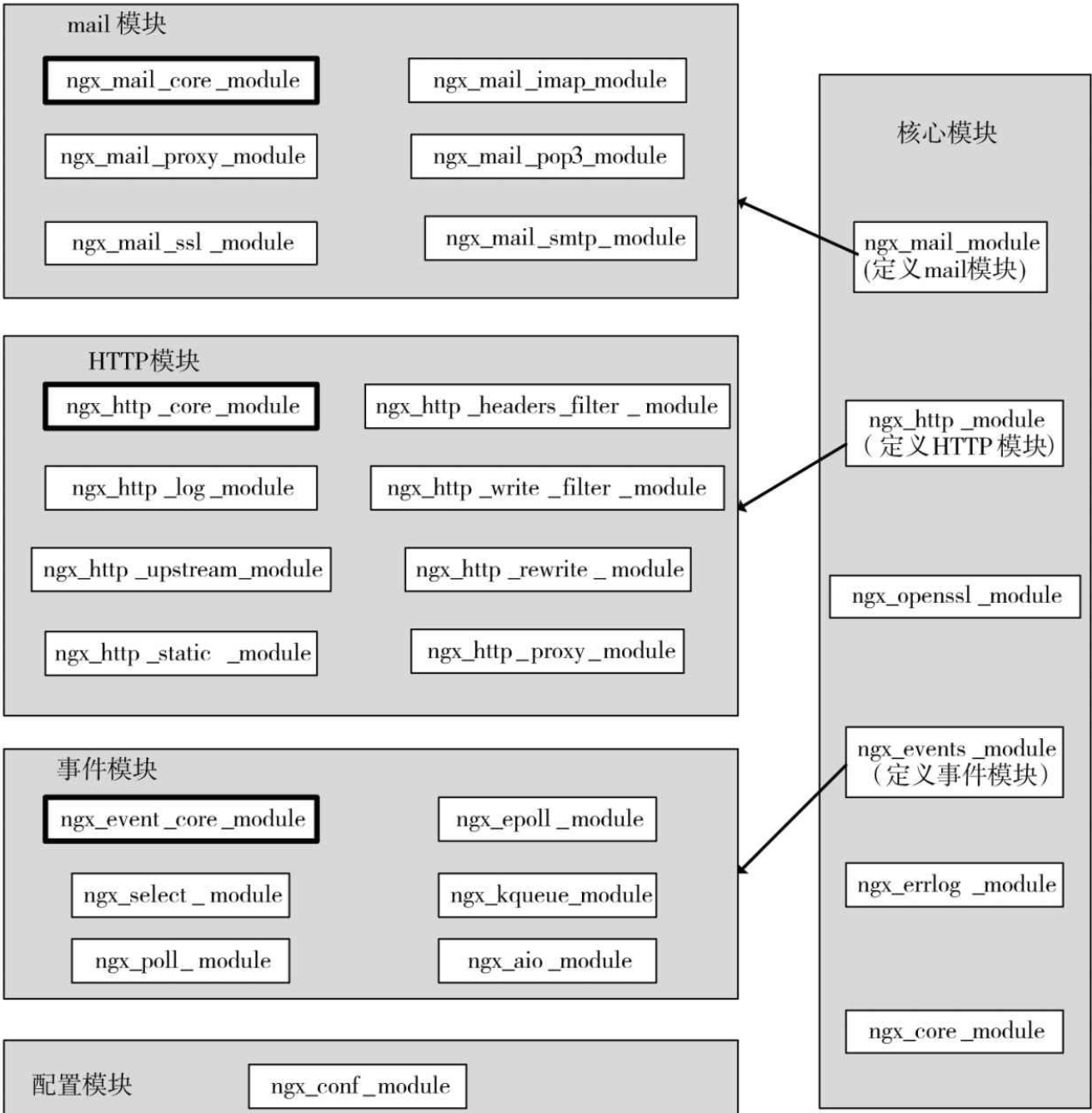
如上图,配置模块和核心模块由Nginx的框架代码定义,配置模块是所有模块的基础,其实现了最基础的配置项解析功能(解析nginx.conf)。Nginx框架还会调用核心模块,但其他3种模块都不会与框架产生直接关系。事件模块、HTTP模块、mail模块的共性为:它们在核心模块中各有一个模块,作为其代言人,并在同类模块中有一个作为核心业务与管理功能的模块。
事件驱动框架
事件驱动指:由一些事件发送源来产生事件,由一个或多个时间收集器来收集、分发时间,然后许多事件处理器会注册自己感兴趣的,同时会消费这些事件。
对于nginx来说,一般会由网卡、磁盘产生事件,事件模块负责收集、分发操作,所有模块都可能是消费者,其首选向事件模块注册感兴趣的事件类型,这样,有事件产生时,事件模块会把事件分发到响应模块中进行处理。
传统Web服务器,采用的事件驱动往往局限于在TCP连接、关闭事件上,一个连接建立后,在其关闭前所有操作都不再是事件驱动,此时会退化为按需执行每个操作的批处理模式,这样,每个请求在连接后都将始终占有系统资源,直到连接关闭才会释放。
Nginx则不然,他不会使用进程或线程作为事件消费者,所谓事件消费者只能是某个模块。只有事件收集器、分发器才有资格占用进程资源,它们会在分发某个事件时调用事件消费模块使用当前占用进程资源。
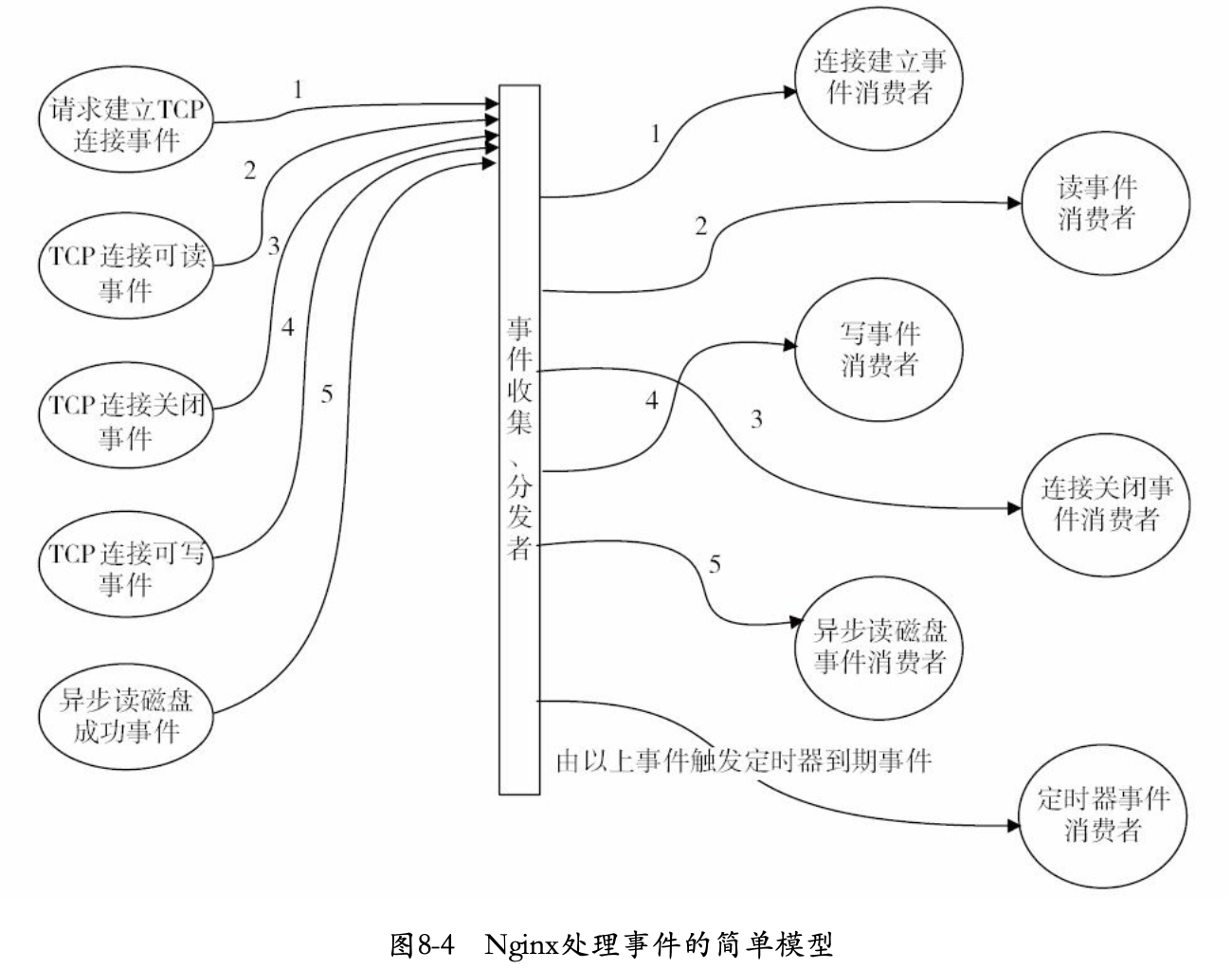
如上图,在事件收集、分发者进程的一次处理过程中,5个事件按序被收集后,将开始使用当前进程分发事件,从而调用响应的事件消费者模块来处理事件。事件消费者只是被事件分发者进程短期调用而已。
请求的多阶段异步处理
请求的多阶段异步处理是指:把一个请求过程按照事件的触发方式划分为多个阶段,每个阶段都可以由事件收集、分发来触发。
请求的多阶段异步处理优势:这种设计配合事件驱动架构,将极地提高网络性能,同时使得每个进程都能全力运转,不会或者尽量少的出现进程休眠状况。
划分请求阶段原则为:找到请求处理流程中阻塞方法,在阻塞代码段上按照下面四个方法来划分阶段:
将阻塞进程的方法按照相关的触发事件分解为两个阶段:
一个本身可能导致进程休眠的方法或系统调用,一般可以分解为多个更小的方法或者系统调用,这些调用间可以通过事件触发关联起来。大部分情况,一个阻塞的方法调用可以划分为两个阶段:第一阶段为,将阻塞方法改为非阻塞方法,并将进程归还给事件分发器;第二阶段,用于处理非阻塞方法最终返回结果,这里的返回结果就是第二阶段触发事件。
例如使用send调用时,如果使用阻塞socket句柄,send向内核发送数据后将使当前进程休眠,直到成功发出数据。可以将send调用划分为两个阶段:使用非阻塞socket句柄,发送后进程不休眠,再将socket句柄加入事件收集器中就可以等待相应事件触发下一阶段,send发送数据被对方接收后会触发send结果返回阶段。
将阻塞方法调用按照时间分解为多个阶段的方法调用
系统中事件收集器、分发器并非可以处理任何事件。例如读取文件调用(非异步I/O),如果我们读取10MB文件,这些文件在磁盘块未必是连续的,此时可能需要多次驱动硬盘寻址,寻址时,进程多半会休眠或等待。如果内核不支持异步I/O时(或未打开),就不能采用第一个方案。此时可以分解读取文件调用:把10MB的文件划分为1000份,每次读取10KB。每次读取10KB的时间是可控的,意味着该事件不会占用进程太久,整个系统可以及时处理其他请求。
在读取0KB-10KB后如何进入10KB-20KB呢,可以有多种方式:如读取完10KB要使用网络进行发送,可以由网络事件进行触发。或者没有网络事件,可以设置一个简单的定时器。
在”无所事事”且必须等待系统响应时,使用定时器划分阶段
有时阻塞代码可以是这样的:进行某个无阻塞的系统调用后,必须通过持续检查标志位来确定是否继续向下执行,当标志位没有获得满足时就循环地检查。此时,应该使用定时器来代替循环检查标志,这样定时器事件发送时就会先检查标志,如果标志不满足,就立即归还进程控制权,同时继续加入期望的下一个定时器事件。
如果阻塞方法完全无法划分,则必须使用独立的进程执行这个阻塞方法
如果某个方法的调用时可能导致进程休眠,或者占用进程时间过长,开始又无法将该方法分级为非阻塞的方法,那么,这与事件驱动框架是相违背的。通常是由于方法实现者未开放非阻塞接口所导致,这时必须通过产生新的进程或者指定某个非事件分发者进程来执行阻塞方法,并在阻塞方法执行完毕时向事件收集、分发者进程发送事件通知继续执行。因此,至少要拆分为两个阶段:阻塞方法执行前阶段、阻塞方法执行后阶段,阻塞方法由单独的进程取调度,并在方法返回后发送事件通知。一旦出现这种情况,应该考虑这样的事件消费者是否合理,有没有必要使用这种违反事件驱动的方式来解决阻塞问题。
管理进程、多工作进程设计
Nginx采用一个master管理进程,多个worker工作进程的设计方式,如下图:
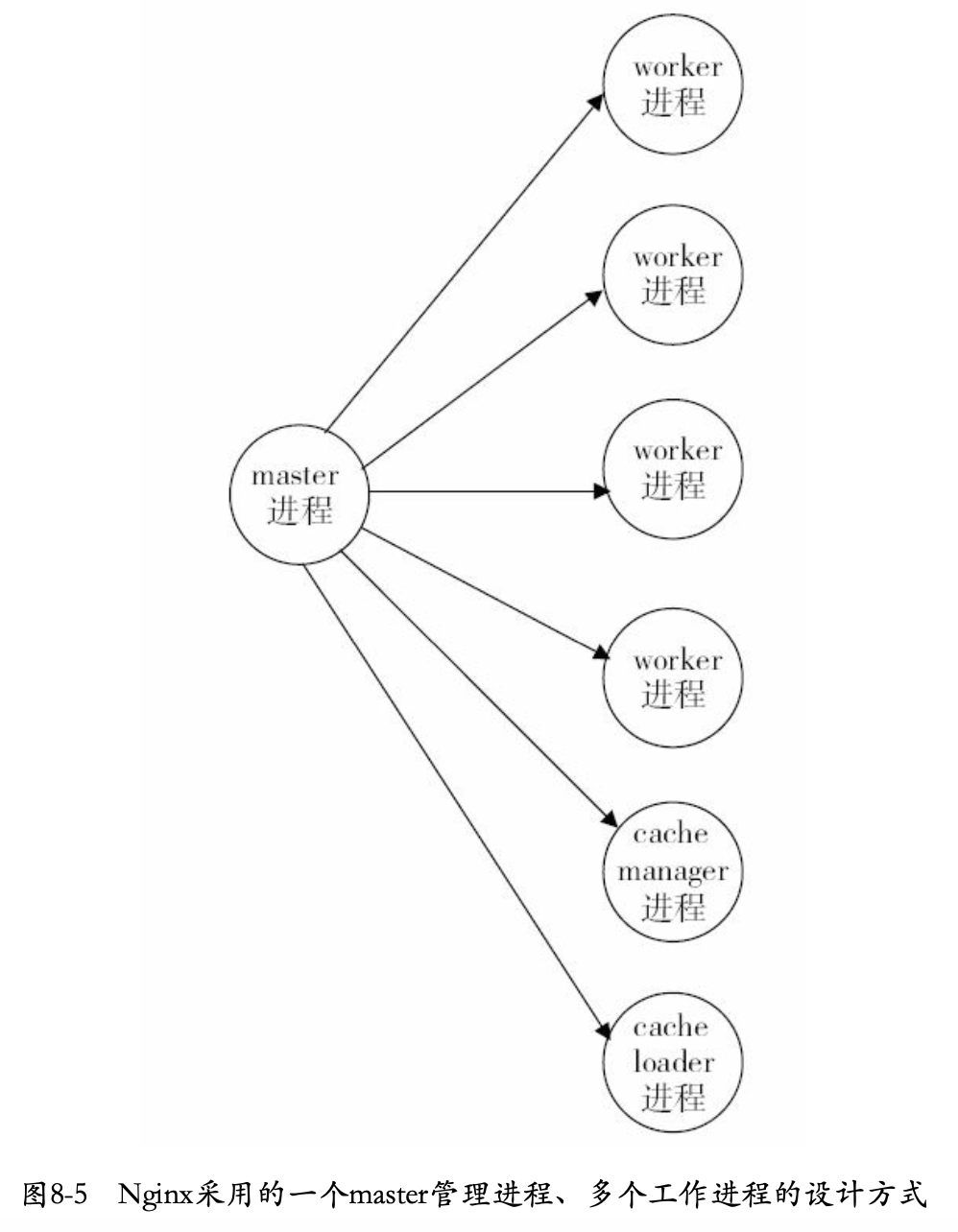
该设计的优点为:
利用多核系统的并发处理能力
负载均衡
每个worker工作进程通过进程间通信来实现负载均衡,即一个请求到达时会更容易地被分配到负载较轻的进程中。
管理进程负责监控工作进程的状态,并负责其行为
管理进程不会占用太多系统资源,其只用来启动、停止、建库或使用其他行为来控制工作进程。首选,这提高了系统的可靠性,当工作进程出现问题时,管理进程可以启动新的工作进程来避免系统性能下降。其次,管理进程支持nginx服务运行中的程序升级、配置项的修改等操作。这种设计使得动态可扩展性、动态定制性、动态可进化性较容易实现。
内存池的设计
为了避免出现内存碎片、减少向操作系统申请内存的次数、降低各个模块的开发复杂度,Nginx设计了简单的内存池。内存池没有很复杂的功能:其通常不负责回收内存池中已经分配的内存。内存池最大的优点在于:把多次向系统申请内存的操作整合到一次,这大大减少了CPU资源消耗,同时减少了内存碎片。
Nginx框架中的核心结构体ngx_cycle_t
Nginx核心的框架代码围绕ngx_cycle_t结构体展开。
ngx_listening_t结构体
作为web服务器,nginx首先需要监听端口并处理其中的网络事件。ngx_cycle_t对象有一个动态数组成员listening,其每个元素都是ngx_listening_t结构体,每个ngx_listening_t结构体代表nginx服务器监听的一个端口。
1 | typedef struct ngx_listening_s ngx_listening_t; |
ngx_connection_handler_pt类型的handler成员表示在这个监听端口上成功建立新的tcp连接后,就会回调handler方法,其定义为:
1 | typedef void (*ngx_connection_handler_pt)(ngx_connect_t *c); |
ngx_cycle_t结构体
首先来介绍一下ngx_cycle_t中的成员(其中connectins、read_events、write_events、files、free_connection成员与事件模块强相关,在事件模块中详细介绍)。
1 | struct ngx_cycle_s { |
ngx_cycle_t支持的方法
每个模块都可以通过init_module、init_process、exit_process、exit_master等方法操作进程的单独的ngx_cycle_t结构体。nginx框架关于ngx_cycle_t结构体方法如下:
| 方法名 | 参数含义 | 执行含义 |
|---|---|---|
| ngx_cycle_t ngx_init_cycle(ngx_cycle_t old_cycle) | old_cycle表示临时的ngx_cycle_t指针,一般用来传递配置文件路径等参数。 | 返回初始化完成的结构体,该函数将会负责初始化ngx_cycle_t中的数据结构、解析配置文件、加载所有模块、打开监听端口、初始化进程间通讯方式等工作。失败返回null。 |
| ngx_init_t ngx_process_options(ngx_cycle_t cycle) | 与上一个参数一致 | 用运行Nginx时可能携带的目录参数来初始化cycle,包括初始化运行目录、配置目录,并生成完整的nginx.conf配置文件路径 |
| ngx_init_t ngx_add_inherited_sockets(ngx_cycle_t cycle) | cycle是当前进程的ngx_cycle_t结构体指针 | 在不重启服务器升级时,老的nginx进程会通过环境变量NGINX来传递需要打开的监听端口,新的nginx进程会通过ngx_add_ingerited_sockets方法来使用已经打开的TCP监听端口 |
| ngx_int_t ngx_open_listening_sockets(ngx_cycle_t *cycle) | cycle是当前进程的ngx_cycle_t结构体指针 | 监听、绑定cycle中listening动态数组指定的相应端口 |
| void ngx_configure_listening_sockets(ngx_cycle_t cycle) | cycle是当前进程的ngx_cycle_t结构体指针 | 根据nginx.conf中的配置项设置已经监听的句柄 |
| void ngx_close_listening_sockets(ngx_cycle_t *cycle) | cycle是当前进程的ngx_cycle_t结构体指针 | 关闭cycle中listening动态数组中已经监听的句柄 |
| void ngx_master_process_cycle(ngx_cycle_t cycle) | cycle是当前进程的ngx_cycle_t结构体指针 | 进入master进程主循环 |
| void ngx_master_single_cycle(ngx_cycle_t *cycle) | cycle是当前进程的ngx_cycle_t结构体指针 | 进入单进程模式的工作循环 |
| void ngx_start_worker_processes(ngx_cycle_t *cycle, ngx_int_t n, ngx_int_t type) | cycle是当前进程的ngx_cycle_t结构体指针,n是启动进程数量,type是启动方式,其取值为如下5个;1)NGX_PROCESS_RESPAWN;2)NGX_PROCESS_NORESPAWN;3)NGX_PROCESS_JUST_SPAWN;4)NGX_PROCESS_JUST_RESPAWN;5)NGX_PROCESS_DEFACHED。type值影响ngx_process_t中respawn,detached,just_spawn标志位值 | 启动n个work子进程,并设置好每个子进程与父进程之间使用socketpair系统调用建立起来的socket句柄通信机制 |
| void ngx_start_cache_manger_processes(ngx_cycle_t *cycle, ngx_nint_t respawn) | cycle是当前进程的ngx_cycle_t结构体指针,respawn与ngx_start_worker_processes的type一致 | 根据是否使用文件缓存模块,即cycle中存储路径的动态数组中是否有路径的manage标志打开,来决定是否启动cache manage子进程,根据loader标志位来决定是否启动cache loader子进程 |
| void ngx_pass_open_channel(ngx_cycle_t cycle, ngx_channel_t ch) | cycle是当前进程的ngx_cycle_t结构体指针,ch是将要发送的信息 | 向所有已经打开的channel(通过socketpair生成的句柄进行通信)发送ch信息 |
| void ngx_single_worker_processes(ngx_cycle_t *cycle, int signo) | cycle是当前进程的ngx_cycle_t结构体指针,signo是信号 | 处理worker进程接受到的信号 |
| ngx_uint_t ngx_reap_children(ngx_cycle_t *cycle) | cycle是当前进程的ngx_cycle_t结构体指针 | 检查master进程的所有子进程,根据每个子进程的状态(ngx_process_t结构体中标志位)判断是否要启动子进程、更改pid文件等 |
| void ngx_master_process_exit(ngx_cycle_t *cycle) | cycle是当前进程的ngx_cycle_t结构体指针 | 退出master进程主循环 |
| void ngx_work_process_cycle(ngx_cycle_t cycle, void data) | cycle是当前进程的ngx_cycle_t结构体指针,data目前还未使用,null | 进入worker进程主循环 |
| void ngx_work_process_init(ngx_cycle_t *cycle, ngx_uint_t priority) | cycle是当前进程的ngx_cycle_t结构体指针,priority是当前worker进程的优先级 | 进入worker进程主循环之前的初始化工作 |
| void ngx_work_process_exit(ngx_cycle_t *cycle) | cycle是当前进程的ngx_cycle_t结构体指针 | 退出worker进程主循环 |
| void ngx_cache_manager_process_cycle(ngx_cycle_t cycle, void data) | cycle是当前进程的ngx_cycle_t结构体指针,data是传入的ngx_cache_manager_ctx_t结构体指针 | 执行缓存管理工作的循环方法。 |
| void ngx_process_events_and_timers(ngx_cycle_t *cycle) | cycle是当前进程的ngx_cycle_t结构体指针 | 使用事件管理模块处理截止到现在已经收集到的事件 |
nginx启动时框架处理流程
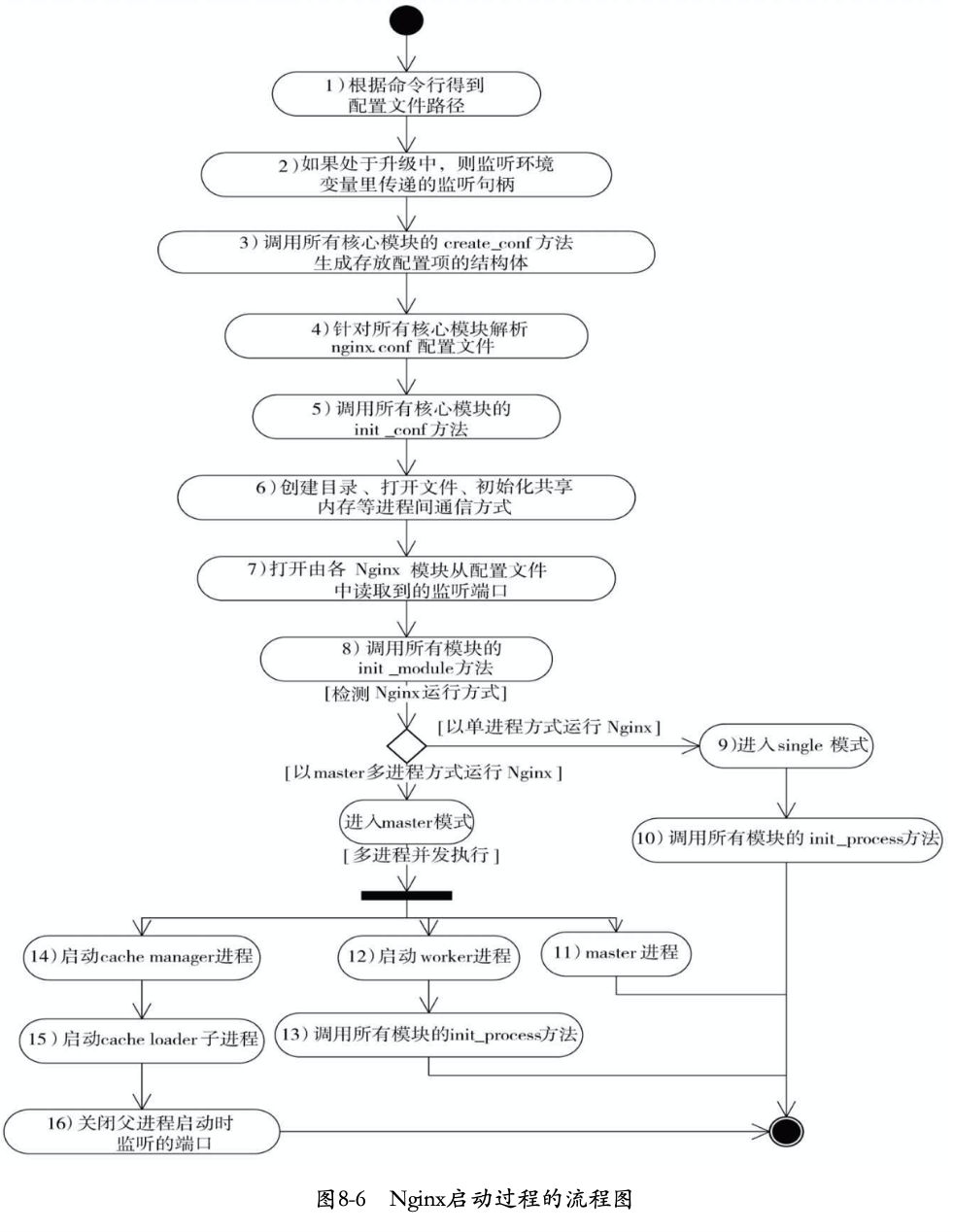
nginx启动过程详解
1 | int ngx_cdecl |
解析启动参数
1 | if (ngx_get_options(argc, argv) != NGX_OK) { |
逐字符解析启动请求参数,根据解析参数设置全局变量。
1 | static ngx_int_t |
初始化信息
1 | ngx_time_init(); |
详见事件处理部分。
初始化log打印描述符
1 | log = ngx_log_init(ngx_prefix); |
更加启动参数或默认log路径,初始化log信息,包括描述符和等级等信息。
申请内存池空间Pool
1 | ngx_memzero(&init_cycle, sizeof(ngx_cycle_t)); |
存储命令行参数
1 | if (ngx_save_argv(&init_cycle, argc, argv) != NGX_OK) { |
将命令行存储到全国变量中:
1 | ngx_argv |
设置相关路径
1 | if (ngx_process_options(&init_cycle) != NGX_OK) { |
通过启动命令行参数或默认值设置cycle中的参数
1 | static ngx_int_t |
初始化系统相关全局变量
1 | if (ngx_os_init(log) != NGX_OK) { |
待详细查看。目前看包括如下数据:
1 | ngx_pagesize = getpagesize(); // 内存分页大小 |
初始化差错校验
1 | if (ngx_crc32_table_init() != NGX_OK) { |
nginx使用CRC:循环冗余检测(Cycle Redundancy Check)来进行差错校验。
初始化slab共享内存
1 | ngx_slab_sizes_init(); |
具体详见slab共享内存。
监听环境变量中的端口
1 | if (ngx_add_inherited_sockets(&init_cycle) != NGX_OK) { |
对于平滑升级来说,需要保证用户无感知,因此要将原本开发监听的套接字存放于环境变量,而后,由新启动的进程读取,重新进行监听。
首选从环境变量NGINX中读取到套接字:
1 | static ngx_int_t |
获取套接字对应的信息ngx_set_inherited_sockets:
1 | getsockname(ls[i].fd, ls[i].sockaddr, &ls[i].socklen); // 获取套接字的sockaddr |
预初始化模块
1 | if (ngx_preinit_modules() != NGX_OK) { |
初始化cycle
1 | cycle = ngx_init_cycle(&init_cycle); |
1 | /* 这里参数ngx_cycle_t被视为old cycle,一方面在不终止服务重新加载配置时会执行该操作,此时会传递一个old的cycle,另一方面,在一个新启动的服务来说,根据之前的操作,已经加载了相应的cycle参数,这里会继承上述获取到的部分参数,并进行升级合并 */ |
创建管理目录
ngx_create_paths。对于需要管理目录的配置,生成相应的目录,例如:http请求包体零时存放路径。
1 | client_body_temp_path dir-path [level1 [level2 [level3]]] |
创建管理文件
ngx_http_log_set_log
1 | { ngx_string("access_log"), |
打开日志文件
1 | static ngx_command_t ngx_errlog_commands[] = { |
打开并设置监听地址
在看这部分之前,应该先查看配置项解析章节,至少需要查看其中的管理监听端口号部分。
ngx_open_listening_sockets打开监听地址
1 | ngx_int_t |
这里需要着重关注一下reuseport属性。对于监听多个地址:不同ip+同一个port,如果未开启该属性时,会失败。例如如下配置:
1 | http { |
这里,对于127.0.0.1:8884这个地址,我们希望进行单独的监听(设置了bind),这时会先单独对该地址进行bind。而后,对于0.0.0.0:8884这个通配符地址来说,我们还要再执行一次bind。但由于未设置reuseport属性,监听0.0.0.0:8884将会出错。改成如下配置则可以正常监听:
1 | http { |
这里,两个地址都设置了reuseport属性,此时可以实现正常监听。由于对每个ip+port形式的地址,nginx维护一个ngx_http_listen_opt_t。因此两个listen都需要加上reuseport才行。注意如下配置也不会有问题:
1 | http { |
这时由于第一个地址并未设置bind。此时不会单独对127.0.0.1:8884创建一个套接字。而是直接在0.0.0.0:8884这个通配符地址上进行监听。对于建立的连接,通过getsockname函数来发现绑定到套接字上的地址,以此来区分使用哪个虚拟服务。
ngx_configure_listening_sockets设置套接字属性
通过setsockopt函数对套接字进行设置。
1 | void |
测试配置的处理
1 | if (ngx_test_config) { |
发送信号处理
1 | if (ngx_signal) { |
1 | ngx_int_t |
具体对接收到信号的处理,后续介绍。
判断运行方式
1 | // 获取配置解析的ngx_core_module解析项 |
信号处理
1 | if (ngx_init_signals(cycle->log) != NGX_OK) { |
1 | typedef struct { |
信号处理相关内容可以查看如下文档:信号处理。其中处理函数为空的函数,即表示不对信号做任何处理,即忽略。其他信号处理函数均为ngx_signal_handler。处理如下:
1 | static void |
对应子进程退出时的处理如下:
1 | static void |
对应进程终止相关处理,可参考如下文档:进程控制。
释放终止进程锁的函数逻辑如下:
1 | static void |
变更运行状态为守护进程
1 | // 非继承而来,即正常启动,并且设置为守护进程运行模式(默认) |
nginx默认为以守护进程的模式运行。关于守护进程,详细信息可以参考如下文档,其实际方法也与其大致相同。守护进程。
创建pid文件
1 | // 对于非继承而来的进程,会创建pid文件,继承而来的进程,已经在init cycle中创建了,详情参考上文。 |
设置运行方式
1 | if (ngx_process == NGX_PROCESS_SINGLE) { |
根据是单进程模式运行还是master-workers方式执行对应的方法。这里我们只看master-worker方式运行。
执行主体循环
根据配置,选择运行方式,分别为单进程方式运行和master-workers方式运行。
1 | if (ngx_process == NGX_PROCESS_SINGLE) { |
具体细节参考master进程和worker进程逻辑。
master进程逻辑
整体处理函数
这里只介绍以master-worker形式运行的情况。其执行入口为如下函数:
1 | void |
对于循环中使用的信号相关变量,参考上文中的信号处理部分。
启动worker子进程
相关数据结构
进程信息ngx_process_t
ngx_process_t结构存储了进程的相关信息。其定义如下:
1 | // 进程执行的处理函数 |
进程间传递信息ngx_channel_t
ngx_channel_t结构用于进程间传递信息,包括直接传递unix域套接字。
1 | typedef struct { |
传递unix域套接字详见;传递文件描述符
全局变量ngx_processes
全局变量ngx_processes存储了每一个子进程当前状态。该数据会在master进程和各个子进程间进行维护(目前子进程只需要关注自己对应的一个元素)。
1 | ngx_process_t ngx_processes[NGX_MAX_PROCESSES]; |
启动函数
使用ngx_start_worker_processes函数来启动子进程。其逻辑如下:
1 | // n为启动子进程数量。type为启动方式 |
ngx_spawn_process
这里ngx_spawn_process函数为创建子进程的统一处理函数。其逻辑如下:
1 | /* proc为子进程运行的函数。data为向子进程传递的额外参数信息,name为子进程名,即操作系统中显示的进程名,当respawn为负数时,表示启动的进程类型,用于控制创建何种进程 当是正数时,表示重启对应ngx_processes下标的进程*/ |
进程间通讯
进程之间通过unix域套接字来传递信息。但在启动函数中有一个问题,即for循环中,在前面创建的子进程将无法拥有在后面创建的子进程的套接字。例如第一个进程(即在ngx_processes中下标为0的进程),将不会有第二个进程(即在ngx_processes中下标为0的进程)中的channel(两个unix域套接字,其中第一个用于其他进程向该进程发送信息,第二个用于进程本身接收信息)信息。这样将导致子进程之间无法直接进行通讯。
虽然目前nginx架构并未使用子进程之间进行通讯(都是matser与子进程进行通讯)。但为了后续的升级,nginx已经支持了子进程之间的通讯,其原理是通过unix域套接字传递文件描述符。具体原理可参考:传递文件描述符。
向之前创建的进程传递unix描述符函数逻辑如下:
1 | static void |
ngx_write_channel
其中详细介绍一下向域套接字写数据。
1 | ngx_int_t |
具体发送域套接字参考:传递文件描述符。
启动cache管理子进程
暂时还未详细阅读,后续补充。
设置时钟信号
对于设置时钟信号,参考https://blog.csdn.net/lixianlin/article/details/25604779
子进程退出时处理
当子进程退出时,将执行ngx_reap_children函数来进行检查。具体逻辑如下:
1 | static ngx_uint_t |
退出master进程
如果是接收到退出信号,并且所有子进程已完成退出,则会执行master进程的退出。
1 | static void |
删除pid文件
会根据是否运行新的二进制文件来删除对应的pid文件。
1 | void |
关闭监听套接字
程序退出会关闭对套接字的监听。其处理逻辑如下:
1 | void |
该函数用到了很多事件相关的处理,详细参考后面关于事件模块的介绍。
向子进程下发指令
master进程通过unix域套接字或者信号下发指令,函数为ngx_signal_worker_processes,其处理逻辑如下:
1 | static void |
对应kill函数,可参考文档:kill和raise.
执行新的二进制文件
执行新的二进制文件函数ngx_exec_new_binary。其处理逻辑如下:
1 | ngx_pid_t |
运行二进制文件
在ngx_execute函数中生成子进程并在子进程执行新的二进制文件。其逻辑如下:
1 | ngx_pid_t |
子进程执行的函数为:
1 | static void |
具体execve执行函数可参考文档:exec函数。注意,这里第一个参数是path,即运行文件的路径,并不会如filename一样,在环境变量的PATH中进行查找。因此,如果运行的nginx是通过环境变量找到的时,例如将nginx可执行文件移动到/urs/bin目录下,在终端直接运行nginx生成的程序,如果要让其升级,一定会失败,即使第三个参数中存在PATH环境变量,这时由于第一个参数是path,并不会在环境变量中查找。因此运行nginx命令,一定要是完整的可执行文件路径。至于如何在第三个参数中增加PATH环境变量,下文详细介绍。
设置环境变量
默认情况下,如果运行的exec系列函数没有环境变量这一参数时,新生成的子进程是直接继承父进程的环境变量表的。具体可参考如下文档:环境表,环境变量,exec函数。
但由于在平滑升级时,我们要向子进程传递正在监听的文件描述符,而传输的方式是通过环境变量进行传递。注意,对于监听的文件描述符,之前并未设置为EXCECLOSE即执行时关闭,因此fork后的子进程运行exec时依然继承父进程的套接字,这时通过getsockname和getsockopt即可获取套接字上对应监听的属性,就可以在子进程中继续监听了。
这样就实现了监听描述符之间的传递,但是这也带来了一下额外的问题,由于要通过环境变量来传递套接字,这将导致子进程无法天然的基础父进程中使用的环境变量,因此我们需要将当前nginx使用的环境变量一起传递给子进程。这一步操作在ngx_set_environment完成,其处理逻辑如下:
1 | /* 参数last用来区分使用创建,(当前)只有在创建子进程运行新的二进制文件时才会传递last为整数,其余均为NULL。last的大小表示除了当前进程需要使用的环境变量意外,需要额外申请的环境变量数组大小, 用于在返回后在环境变量中增加额外信息,如需要传递的套接字 */ |
配置中环境变量的解析
上述的程序中大量使用的ngx_core_module模块的ccf->env数据,这里有必要介绍一下环境变量配置的解析处理逻辑
环境变量的配置语法如下:
1 | env name |
对于只有name的情况,表示我们要使用name对应的系统环境变量,对应name和value组的情况,表示我们要设置的对应name的环境变量在运行时的值。env只是变更了环境变量,更改了运行时的环境变量,如果希望在处理时,将环境变量作为一个值使用,例如作为server_name使用,则还需要额外的模块进行处理(如perl和lua模块),这里不做详细介绍。
ngx_core_module模块如下:
1 | ngx_module_t ngx_core_module = { |
其中设置环境变量的函数如下:
1 | static char * |
这里有个问题是,记录的环境变量值并非一定是完整的配置文件中设置的值。这是由于配置文件中env有两个作用,一个是设置环境变量,另一个是使用环境变量。当我们只是写明了环境变量的key,如
1 | env PATH |
表示,我们要使用系统的PATH环境变量,其值为系统定义的值。
当我们写明的是环境变量的key和值时,表明我们要使用的环境变量,并且设置其值。如:
1 | env PATH=/usr/bin |
表明执行的二进制文件的PATH环境变量值为/usr/bin。
如何区分二者呢,nginx就通过查看设置的值是否存在=进行区分。同时,为了方便后续使用,将len设置为等号的位置用于区分是使用环境变量还是设置环境变量。直接判断data[len]是否等于=即可。
worker进程逻辑
ngx_master_process_cycle函数会创建指定数量的的worker进程,每个进程执行的处理函数为ngx_worker_process_cycle,其执行逻辑如下:
1 | // data为对应worker进程的id。从0开始连续整数 |
work进程初始化
执行worker循环之前,会先对worker进行初始化操作。其逻辑如下:
1 | static void |
绑定进程到指定CPU
进程绑定 CPU 的好处:在多核 CPU 结构中,每个核心有各自的L1、L2缓存,而L3缓存是共用的。如果一个进程在核心间来回切换,各个核心的缓存命中率就会受到影响。相反如果进程不管如何调度,都始终可以在一个核心上执行,那么其数据的L1、L2 缓存的命中率可以显著提高。
所以,将进程与 CPU 进行绑定可以提高 CPU 缓存的命中率,从而提高性能。而进程与 CPU 绑定被称为:CPU 亲和性。
linux使用sched_setaffinity系统调用实现:
1 | int sched_setaffinity(pid_t pid, size_t cpusetsize, const cpu_set_t *mask); |
pid为要设置的进程id,如果是0,则是调用进程本身的进程id。
cpusetsize为mask参数的大小。
mask参数是一个位图,每个位对应一个CPU,当某个位置1时,指示进程绑定到对应CPU上运行,一个进程可以绑定多个CPU。
如下函数检查和设置mask:
1 | typedef struct |
下面看一下nginx中设置进程绑定到cpu上。
配置解析
在ngx_core_module模块中进行解析。
通过配置worker_cpu_affinity来设置绑定关系。该值也可以是auto,其解析逻辑如下:
1 | { ngx_string("worker_cpu_affinity"), |
获取进程绑定的cpu
1 | ngx_cpuset_t * |
设置绑定
1 | void |
unix域套接字通信事件
在执行初始化的最后,会将与其他进程交互的套接字事件添加进入事件监控中。其逻辑如下:
1 | ngx_int_t |
ngx_channel_handler可读事件触发时处理
1 | static void |
读取unix域数据
1 | ngx_int_t |
ngx_worker_process_exit进程退出
1 | static void |
ngx_set_shutdown_timer设置关机时间
当配置的show_down字段时,会在优雅的关机时增加一个超时时间,用于加快关机,其逻辑如下:
1 | void |
其中handler处理函数如下:
1 | static void |
ngx_close_listening_sockets关闭正在监听套接字
1 | void |
ngx_close_idle_connections关闭空闲连接
1 | void |
ngx_reopen_files重新打开日志文件
1 | void |
在使用open打开文件时,使用O_APPEND,保证多进程输入不会发送混乱。
在执行日志回滚时,应该先将旧文件移动到新的位置,在向master进程发送reopen信号。这时处理逻辑是,会先将缓冲区的内容写到旧的文件中。然后重新打开文件时发现文件不存在,新建文件,之后再关闭旧的文件描述符,之后使用新的文件描述符。
ngx_process_events_and_timers事件处理
1 | void |
负载均衡主要通过原子变量ngx_use_accept_mutex和ngx_accept_disabled控制。ngx_accept_disabled是一个整数,初始化为0,每次新连接建立时会根据当前连接数量对该值赋值:ngx_cycle->connection_n / 8 - ngx_cycle->free_connection_n即所有连接数的百分之一减去当前空闲连接。当负载过高时,空闲连接将会减少,当八分之七的连接已经使用时,该值将变成正值,这时循环中将不再获取负载均衡锁,即不再建立新的连接,而是将该值减一,直到到0才继续接收连接。
ngx_trylock_accept_mutex获取负载均衡锁
该方法会尝试获取负载均衡锁,并将监听套接字对应事件添加到事件驱动中。其逻辑如下:
1 | ngx_int_t |
注意在每次循环中,如果获取到负载均衡锁了,只会是否锁,并不会将监听事件从epoll中去除。只会在下一次循环中,未获取到负载均衡锁时才从中删除。这应该是处于效率考量的,如果其他进程负载都交高是,某一个负载较低的进程则很可能在多次循环中都能够获取到负载均衡锁,这时采用上述方法就不用每次都执行添加事件和删除事件了。
ngx_enable_accept_events添加监听套接字对应事件到事件驱动模块
注意不是所有监听套接字都需要使用该方法进行添加。对于不使用负载均衡锁来说,不用该方法。对应设置了端口可复用的套接字来说,会为每一个进程拷贝一份监听套接字,每个进程单独进行监听,操作系统提供负载均衡操作(具体查看事件模块的ngx_event_core_module模块和ngx_events_module模块的介绍)。
其处理逻辑如下:
1 | ngx_int_t |
ngx_disable_accept_events从事件驱动中删除监听套接字对应事件
与添加一样,也是只能删除该删除的,对应端口复用的不能删除:
1 | // all如果为1,则是删除所有时间 |
ngx_event_process_posted执行post队列中时间
1 | void |
HTTP请求处理流程
在worker进程启动时会调用事件核心模块,监听网络请求,在接收到请求和首先会执行ngx_event_accept监听事件回调方法。下面就按照该方法逐一讲解http处理流程。
主要结构
ngx_http_request_t请求结构
1 | struct ngx_http_request_s { |
建立连接
1 | void |
数据交互
其中读取和写入函数如下:
1 |
其中ngx_io初始化在ngx_epoll_init方法中:
1 | ngx_io = ngx_os_io; |
其中ngx_os_io定义如
1 | typedef struct { |
接收数据ngx_unix_recv
1 | // buf为接收数据的起始地址,size为最大长度 |
连接处理
数据结构
这里大部分数据结构都已经在解析配置中介绍过了,可以查看对应部分。这里还有一个结构为ngx_http_connection_t结构。
ngx_http_connection_t
定义如下:
1 | typedef struct { |
函数方法ngx_http_init_connection
在建立连接后调用listen结构的handler方法进行处理。handler方法定义在ngx_http_add_listening方法中,具体参考配置解析中的监听端口部分。定义的函数为ngx_http_init_connection。具体方法逻辑如下:
1 | void |
获取请求地址
由于对应通配符监听来说,一个监听端口上可能监听了多个ip+port的地址,这时需要获取用户实际请求的ip地址,来获得对应的配置,函数方法为ngx_connection_local_sockaddr:
1 | ngx_int_t |
关于套接字地址相关信息,可以查看如下文章:套接字地址。
ngx_http_wait_request_handler获取请求
相关结构
ngx_proxy_protocol_s
ngx_proxy_protocol_s结构用于存储proxy_protocol协议的相关信息。proxy protocol是HAProxy的作者Willy Tarreau于2010年开发和设计的一个Internet协议,通过为tcp添加一个很小的头信息,来方便的传递客户端信息(协议栈、源IP、目的IP、源端口、目的端口等),在网络情况复杂又需要获取用户真实IP时非常有用。其本质是在三次握手结束后由代理在连接中插入了一个携带了原始连接四元组信息的数据包。
proxy protocol的接收端必须在接收到完整有效的 proxy protocol 头部后才能开始处理连接数据。因此对于服务器的同一个监听端口,不存在兼容带proxy protocol包的连接和不带proxy protocol包的连接。如果服务器接收到的第一个数据包不符合proxy protocol的格式,那么服务器会直接终止连接。
传输数据格式为:
1 | PROXY TCP4 202.112.144.236 10.210.12.10 5678 80\r\n |
存储相应数据的结构为:
1 | struct ngx_proxy_protocol_s { |
处理方法
指向完成对连接的处理后,将会等待用户下发请求,对应事件处理函数为:
1 | static void |
创建请求结构
1 | ngx_http_request_t * |
1 | static ngx_http_request_t * |
处理请求行
相关结构
ngx_http_headers_in_t
ngx_http_headers_in_t结构存储解析后的请求头。定义如下:
1 | typedef struct { |
执行方法
1 | static void |
关闭请求ngx_http_close_request
1 | static void |
释放关闭请求的逻辑如下:
1 | void |
读取请求行ngx_http_read_request_header
1 | static ssize_t |
解析请求ngx_http_parse_request_line
解析http请求头需要参考http请求协议查看,可以参考http协议。
其中nginx支持了scheam url,对于schema url来说,传递的url字段为:
1 | schema://host:port/uri |
这里shema为Schema协议名称,host为地址,port为端口号,后面的为uri。
1 | ngx_int_t |
解析uri ngx_http_process_request_uri
解析uri主要是拆分参数和前面的uri,并对复杂uri进行处理:
1 | ngx_int_t |
获取请求的服务 ngx_http_set_virtual_server
通过host获取对应的服务:
1 | static ngx_int_t |
根据hostname查找服务的方式如下,参考解析配置相应部分:
1 | static ngx_int_t |
执行子请求方法ngx_http_run_posted_requests
1 | void |
分配大请求内存ngx_http_alloc_large_header_buffer
当原本申请的存储请求头的空间不够时,将调用该函数获取更大的空间。
1 | static ngx_int_t |
处理请求头ngx_http_process_request_headers
1 | static void |
解析请求头ngx_http_parse_header_line
1 | ngx_int_t |
部分请求头处理函数
这里简单介绍一下请求头的处理。
1 | typedef struct { |
具体调用解析的方式见配置解析中的介绍,这里主要介绍一些函数的处理逻辑。
host处理方法ngx_http_process_host
host处理方法主要是解析是否为合法host,并根据host确定服务。
1 | static ngx_int_t |
Connection处理方法ngx_http_process_connection
connection处理方法主要判断请求类型,分为close和keep-alive两种,分别表示请求相应后是否关闭连接。
1 | static ngx_int_t |
Content-Length&Transfer-Encoding处理方法ngx_http_process_unique_header_line
对应post请求来说,需要在接收完成请求头后告知服务器请求体数据长度,该值应该是精确的。如果该值大于实际长度时,服务器会陷入等待中,不会发送响应。当该值小于实际长度时,服务器将只读取到部分数据,如果这时使用了keep-alive形式连接,剩下的部分会在第二次请求中被读取到,导致下一次请求也失败。
但又是,我们可能没办法确定实际要发送的内容大小,这时就不能使用Content-Length头了,而应该使用Transfer-Encoding:chunked。数据以一系列分块的形式进行发送. Content-Length 首部在这种情况下不被发送. 在每一个分块的开头需要添加当前分块的长度, 以十六进制的形式表示,后面紧跟着 \r\n , 之后是分块本身, 后面也是\r\n. 终止块是一个常规的分块, 不同之处在于其长度为0.
处理方法ngx_http_process_unique_header_line是很多请求头的处理方法,只有有唯一值:
1 | static ngx_int_t |
keep-alive处理方法ngx_http_process_header_line
keep-alive指示长连接相关属性,例如:Keep-Alive: 100表示这个TCP通道可以保持100s。keep-alive模式下客户端获取响应结束的方法与服务器获取请求体长度方法一致。如果是静态的响应数据,可以通过判断响应头部中的Content-Length 字段,判断数据达到这个大小就知道数据传输结束了。但是返回的数据是动态变化的,服务器不能第一时间知道数据长度,这样就没有 Content-Length 关键字了。这种情况下,服务器是分块传输数据的,Transfer-Encoding:chunk,这时候就要根据传输的数据块chunk来判断,数据传输结束的时候,最后的一个数据块chunk的长度是0。
HTTP的Keep-Alive与TCP的Keep Alive,有些不同,两者意图不一样。前者主要是 TCP连接复用,避免建立过多的TCP连接。而TCP的Keep Alive的意图是在于保持TCP连接的存活,就是发送心跳包。隔一段时间给连接对端发送一个探测包,如果收到对方回应的 ACK,则认为连接还是存活的,在超过一定重试次数之后还是没有收到对方的回应,则丢弃该 TCP 连接。
对于ngx_http_process_header_line处理方法也是十分通用的头处理逻辑:
1 | static ngx_int_t |
处理请求头ngx_http_process_request_header
1 | ngx_int_t |
请求处理ngx_http_process_request
接收完请求头后进行请求处理,是nginx核心逻辑部分。执行方法如下:
1 | void |
由于nginx基本都是非阻塞试函数,在完全请求解析前,每次调用请求解析函数无法立即完成处理,将会立即返回,在epoll事件启动中接收到读事件时,继续调用解析请求头的处理。这是对于读事件的处理,在解析请求头期间,写事件只是一个空函数,并无任何处理逻辑。
在接收完请求后,对应的读写事件就发生了变更,这里变成了ngx_http_request_handler方法,该函数主要是判断epoll返回的事件类型,来执行对应的请求的读事件处理和写事件处理。这里读事件只是一个空函数,在完成请求前不应该出现可读事件,即使出现,也不会做任何处理。写事件是每次epoll返回都会触发的事件,因此在结束请求前,每次都会执行对应请求的写事件。
写事件的处理会在ngx_http_handler根据当前请求类型来决定,处理方法如下:
设置请求处理ngx_http_handler
1 | void |
核心处理循环ngx_http_core_run_phases
1 | void |
再来看一下具体的读写事件的处理逻辑:
epoll事件触发执行方法ngx_http_request_handler
1 | static void |
核心处理阶段
这里需要参考配置解析中关于处理阶段的处理。在处理方法是,会执行没一个阶段的checker方法。下表了列出了每个阶段的含义及checker方法,下面会详细介绍。
| 阶段 | 含义 | checker方法 |
其他 |
|---|---|---|---|
NGX_HTTP_POST_READ_PHASE |
收到完整的http头部后处理的阶段 | ngx_http_core_generic_phase |
允许用户增加处理函数 |
NGX_HTTP_SERVER_REWRITE_PHASE |
重写uri阶段,这里是在执行uri查找对应的location之前的重写uri。比如在server层定义了一个if语句,根据指定的uri进行重写。 |
ngx_http_core_rewrite_phase |
允许用户添加处理 |
NGX_HTTP_FIND_CONFIG_PHASE |
依据uri查找对应location服务 | ngx_http_core_find_config_phase |
不允许用户自定义函数 |
NGX_HTTP_REWRITE_PHASE |
在location中重写uri | ngx_http_core_rewrite_phase |
允许用户自定义处理函数 |
NGX_HTTP_POST_REWRITE_PHASE |
用于rewrite重新URI后,防止错误的配置导致死循环 | ngx_http_core_post_rewrite_phase |
仅在使用了location重写时才存在该阶段,且不允许用户添加处理方法。 |
NGX_HTTP_PREACCESS_PHASE |
处理NGX_HTTP_ACCESS_PHASE阶段决定访问权限前,http模块可以介入的阶段 | ngx_http_core_generic_phase |
允许用户自定义处理方法。 |
NGX_HTTP_ACCESS_PHASE |
让HTTP模块判断是否允许这个请求访问nginx服务 | ngx_http_core_access_phase |
允许用户自定义处理方法。 |
NGX_HTTP_POST_ACCESS_PHASE |
如果http模块的handler处理函数返回不允许访问的错误码时,这里负责向用户发送拒绝服务的错误 | ngx_http_core_post_access_phase |
仅使用·了权限解析时才存在该步骤,且不允许用户自定义处理函数。 |
NGX_HTTP_PRECONTENT_PHASE |
主要用于try_file | ngx_http_core_generic_phase |
允许用户自定义处理函数 |
NGX_HTTP_CONTENT_PHASE |
用于处理HTTP请求内容的阶段,是大部分http模块介入的阶段 | ngx_http_core_content_phase |
允许用户自定义处理函数。用户主要介入的处理阶段。 |
NGX_HTTP_LOG_PHASE |
处理完成后记录日志的阶段 | ngx_http_core_generic_phase |
允许用户自定义处理函数。 |
首先这里介绍一下多个阶段共用的ngx_http_core_generic_phase的check方法。
ngx_http_core_generic_phase方法
1 | ngx_int_t |
对应使用该方法作为checker的阶段来说,每个处理函数的方法值含义如下:
| 返回值 | 含义 | |
|---|---|---|
NGX_OK |
执行下一个阶段的第一个handler处理方法,这意味着,即使当前阶段后续还有一些HTTP模块设置了handler处理方法,也不会被执行。 | |
NGX_DECLINED |
当前处理函数完成,执行下一个handler方法。 | |
| `NGX_AGAIN | NGX_DONE` | 当前处理函数未完成,存在阻塞调用,将控制权交给事件模块,在下次事件模块触发时,再次调用该方法。 |
| 其他 | 出错,使用ngx_http_finalize_request结束请求。 |
NGX_HTTP_POST_READ_PHASE阶段
完成请求解析后,首先执行的阶段,目前默认的nginx下不会使用该阶段。checker方法为ngx_http_core_generic_phase上文已详细介绍。官方模块的ngx_http_realip_module设置了该方法。这里不做详细介绍。
NGX_HTTP_SERVER_REWRITE_PHASE阶段
NGX_HTTP_SERVER_REWRITE_PHASE阶段主要由ngx_http_rewrite_module模块处理。
首先来看一下该阶段的checker方法。
ngx_http_core_rewrite_phase方法
1 | ngx_int_t |
从上述代码可以看出,该阶段的处理函数方法值对应的含义为:
| 返回值 | 含义 |
|---|---|
NGX_DECLINED |
当前处理函数完成,处理下一个函数 |
NGX_DONE |
当前处理函数未完成,存在阻塞调用,将控制权交给事件模块,在下次事件模块触发时,再次调用该方法。 |
| 其他 | 使用ngx_http_finalize_request结束请求 |
这里的执行方法只有rewrite模块增加的处理函数:
1 | static ngx_int_t |
该部分需要配合rewrite模块的介绍查看。
需要注意的是,当前请求r中的**main_conf,**srv_conf,**loc_conf所处的层级与当前执行阶段一致。对应处于server rewrite阶段来说,这三个配置是server层级解析出的配置,因此执行的处理函数是server层级配置的rewrite模块相关配置方法。(在之前的处理中,通过Server name查找到的配置,赋值就是server层级,详见ngx_http_set_virtual_server函数)。对于location rewrite执行阶段来说,这三个配置是location层级解析出的配置,因此执行的处理函数是location层级配置的rewrite模块相关配置方法(在NGX_HTTP_FIND_CONFIG_PHASE阶段找到请求对应的location块后会重新对配置进行赋值,详见ngx_http_update_location_config方法)。
这里方法的值为e->status,因此如果配置了重定向时,该值会是重定向的返回码,这时会立即结束请求。在解析错误时,也需要设置e->status,以此来立即结束请求。
NGX_HTTP_FIND_CONFIG_PHASE阶段
该阶段checker方法为ngx_http_core_find_config_phase:
1 | ngx_int_t |
从上面代码可以看出该阶段,查找location时返回值对应的含义如下:
| 返回值 | 含义 |
|---|---|
NGX_ERROR |
查找错误,结束请求 |
NGX_DONE |
请求重定向,结束请求,向用户返回重定向 |
| 其他 | 完成当前处理函数,执行后面的处理函数 |
查找location方法ngx_http_core_find_location
该函数负责通过uri查找location。其中返回值含义如下:
1 | /* |
该部分需要节后配置解析一起查看。
执行逻辑如下:
1 | static ngx_int_t |
从上述代码可以看出,location匹配顺序为:精准匹配 > 正则匹配 > 前缀匹配
在精准匹配和前缀中查找的逻辑如下:
1 | /* |
更新请求ngx_http_update_location_config
该方法根据uri查找到的location配置,来更新对请求的限制。
1 | void |
NGX_HTTP_REWRITE_PHASE阶段
该阶段是在location中设置了重写时的处理。
其使用的checker方法和handler方法与NGX_HTTP_SERVER_REWRITE_PHASE阶段一致。这里需要注意的是,这时使用的配置是location层级的配置。
NGX_HTTP_REWRITE_PHASE阶段
NGX_HTTP_REWRITE_PHASE阶段用于在location阶段后判断是否需要再次进行查找。
check方法为:ngx_http_core_post_rewrite_phase,逻辑如下:
1 | ngx_int_t |
NGX_HTTP_PREACCESS_PHASE
该阶段一般针对当前请求进行限制。其处理checker为通用的ngx_http_core_generic_phase,方法这里不做详细介绍。其中执行的模块主要有ngx_http_limit_conn_module和ngx_http_limit_req_module模块,这里主要介绍一下ngx_http_limit_req_module模块的实现。
对于ngx_http_limit_req_module模块的具体实现和介绍,参考一些重要模块中对该模块的介绍。
NGX_HTTP_ACCESS_PHASE阶段
该阶段进行权限的校验。
checker丰富为:ngx_http_core_access_phase
1 | ngx_int_t |
从中我们可以看出该阶段处理函数返回值对应的含义如下:
| 返回值 | 含义 |
|---|---|
NGX_OK |
如果设置satisfy为all,则按顺序执行下一个处理方法,如果设置satisfy为any则执行下一阶段的处理方法。 |
NGX_DECLINED |
按顺序执行下一阶段的处理方法 |
NGX_AGAIN/NGX_DONE |
当前的处理未完成,将控制权交还epoll,下次继续执行当前处理方法。 |
NGX_HTTP_FORBIDDEN/NGX_HTTP_UNAUTHORIZED |
如果设置satisfy为all,结束请求,如果设置satisfy为any则设置access_code成员,并执行下一个处理方法。 |
其他、NGX_ERROR |
结束请求 |
该阶段的模块主要包括ngx_http_access_module模块,ngx_http_auth_basic_module模块和ngx_http_auth_request_module模块。其中前两个模块较为简单,最后一个模块涉及subrequest(后续会详细介绍),因此这里都不做详细介绍。这里只简单介绍一下使用。
ngx_http_access_module
该模块通过简单的配置来限制请求来源的ip。例如:
1 | location / { |
ngx_http_auth_basic_module
ngx_http_auth_basic_module 模块允许通过使用“HTTP 基本身份验证”协议验证用户名和密码来限制对资源的访问。
ngx_http_auth_request_module
ngx_http_auth_request_module 模块根据子请求的结果实现客户端授权。 如果子请求返回 2xx 响应码,则允许访问。 如果返回 401 或 403,则访问被拒绝并返回相应的错误代码。 子请求返回的任何其他响应代码都被视为错误。
NGX_HTTP_POST_ACCESS_PHASE阶段
该阶段对NGX_HTTP_ACCESS_PHASE阶段的结果进行处理。不允许用户插入处理函数。checker方法如下:
1 | ngx_int_t |
NGX_HTTP_PRECONTENT_PHASE阶段
该阶段以前主要是try_files的处理,现在在次基础上增加了ngx_http_mirror_module模块,其checker方法为通用的ngx_http_core_generic_phase方法。对应try_file的处理也相对简单,这里也不做详细介绍。
NGX_HTTP_CONTENT_PHASE阶段
该阶段为核心http处理阶段,该阶段允许用户重新定义nginx服务的行为,是大部分模块介入的阶段。其checker方法如下:
1 | ngx_int_t |
上面展示了为何自定义模块可以直接介入该模块的处理方法。对于模块直接通过handler方式介入,后续会在代理转发中详细介绍,这里先简单看一下结构自定义的一些处理逻辑,表示在没有handler处理情况下的一些默认处理。
这里简单介绍一下ngx_http_static_module模块,看一下架构自定义的处理函数,并引出如何向客户端返回结果,为下一章节做一个铺垫。
ngx_http_static_module模块
模块的作用就是读取磁盘上的静态文件,并把文件内容作为产生的输出。其实现为,根据用户的uri和nginx运行目录,查找是否有对应的文件,如果有,则向用户返回对应的文件,如果是一个目录,则交给ngx_http_autoindex_handler模块处理(也是该阶段的默认处理逻辑)可以列出这个目录的文件,或者是ngx_http_index_handler如果请求的路径下面有个默认的index文件,直接返回index文件的内容。
1 | static ngx_http_module_t ngx_http_static_module_ctx = { |
该模块的处理相当简单,甚至没有comands配置。其postconfiguration方法也十分简单,功能只有一个,就是将ngx_http_static_handler方法添加到NGX_HTTP_CONTENT_PHASE阶段的处理函数数组中。
ngx_http_static_handler方法
这里仅简单介绍处理方法,详细细节可查看对应源码:
1 | static ngx_int_t |
NGX_HTTP_LOG_PHASE阶段
该阶段赋值写日志,这里不做详细介绍。需要注意的是,无论请求在合阶段结束,正常都会在结束时执行该阶段的处理函数。
发送响应
相关结构
ngx_http_headers_out_t响应头
ngx_http_headers_out_t结构存储了响应头信息,其定义如下:
1 | typedef struct { |
发送响应头ngx_http_send_header
函数执行逻辑为:
1 | ngx_int_t |
发送响应体ngx_http_output_filter
该函数用来发送响应体。
1 | ngx_int_t |
发送响应过滤模块
对于发送响应来说,分为发送响应头和响应体,这两个发送响应模块均支持用户自定义处理逻辑,对于定义的处理逻辑来说,使用ngx_http_top_header_filter和ngx_http_next_header_filter来串联响应头发送链表,使用ngx_http_top_body_filter和ngx_http_next_body_filter串联请求体发送响应链表。
过滤模块的处理函数定义为:
1 | typedef char *(*ngx_conf_post_handler_pt) (ngx_conf_t *cf, |
任意一个模块想要介入请求头或请求体的处理,只需要踏进如下函数即可(以ngx_http_gzip_filter_module模块举例):
1 | typedef ngx_int_t (*ngx_http_output_header_filter_pt)(ngx_http_request_t *r); |
从上述代码可以看出nginx如果将各个模块的响应头filter函数和响应体filter串联起来。
其中ngx_http_top_header_filter和ngx_http_top_body_filter模块存储了当前设置的响应头和响应体处理函数,ngx_http_next_header_filter和ngx_http_next_body_filter是作用域为文件作用域的static函数值。当该模块希望在处理响应头和响应体之前先按照该模块进行处理,则向让ngx_http_next_header_filter和ngx_http_next_body_filter存储之前旧的处理方法,再设置ngx_http_top_header_filter和ngx_http_top_body_filter为本模块的新的处理方法。在执行本模块的逻辑之后,执行ngx_http_next_header_filter和ngx_http_next_body_filter方法,即原来的ngx_http_top_header_filter和ngx_http_top_body_filter方法。这样就成功将本模块的处理方法加到了处理序列的头部。
通过这种方式,将所有希望对响应头和响应体执行处理的方法进行串联。因此这时处理的顺序就十分重要,每个模块的添加阶段都是在ctx的postconfiguration方法中,并且每个模块总是将本模块的处理方法添加到序列的头部,因此处理顺序与每个模块执行postconfiguration方法的顺序相反:
1 | &ngx_http_write_filter_module, |
上述为官方定义的响应filter处理模块及其顺序,因此实际执行的顺序与上述顺序相反。
这里比较典型的,常用的模块是ngx_http_headers_filter_module模块和ngx_http_gzip_filter_module模块。
ngx_http_headers_filter_module模块支持通过配置add_header参数。来增加响应头,例如支持跨域配置:
1 | location / { |
ngx_http_gzip_filter_module模块用来对响应进行gzip压缩。要使用gzip压缩时,首先会在header方法中增加响应头:
1 | Content-Encoding:gzip |
在下发响应体时,会按照设置的gzip进行压缩。
其中ngx_http_write_filter_module和ngx_http_header_filter_module分别定义了最后的响应体处理函数和响应头处理函数,后续会专门进行详细讲解。其中定义的发送响应头和响应体函数分别为:ngx_http_write_filter和ngx_http_header_filter,其ngx_http_write_filter为实际传输数据的处理方法,ngx_http_header_filter方法在完成请求头的拼接序列化后,也会调用ngx_http_write_filter方法。
这里有一个是否重要的需要注意的点,即nginx是全异步多阶段处理模式,因此在发送响应时也是不允许阻塞的。在发送响应头时,是不能存在阻塞的函数的,即下发的过程中,每个处理函数应该都不能是阻塞的,直到最终执行数据发送阶段即ngx_http_write_filter函数阶段。对于只有响应只有响应头来说,如果在该阶段存在阻塞,则会设置请求的写事件为ngx_http_write方法,调用事件驱动来进行后续的数据发送。
对于存在响应体的响应来说,如果发送响应头时执行的ngx_http_write_filter方法是阻塞的,则会将未传输的数据添加到请求的out结构中,后续发送响应体时,会向out中再添加数据,并将写事件添加到事件模块中,通过事件发送响应。
需要着重注意的是,发送请求响应的filter链表会执行多次,因此需要每个函数自己来实现避免重复执行。
发送请求响应filter被执行多次的原因主要有如下原因:
- 仅需要发送响应头,但响应头未一次下发完全,此时会将请求的写事件设置为
ngx_http_writer方法,该方法被执行时将调用ngx_http_output_filter方法,执行发送响应头请求链路,但这时其实是没有新数据增加的,只需要吧out链表中未传输的数据发送出去即可,所以方法中的参数in为null。所有这时避免重复执行的方式有两种:1)通过查看是否响应只有请求头,即header_only是否为1。2)通过查看in参数是否为空,为空表示没有新要增加的传输数据需要处理。 - 在需要发送响应体时,响应体在第一次调用
ngx_http_output_filter时已经处理完成了,要全部在参数in包含的链表中了,但是并没有一次完成传输的发送。这时会将请求的写事件设置为ngx_http_writer方法,该方法被执行时将调用ngx_http_output_filter方法,执行发送响应头请求链路,但这时其实是没有新数据增加的,只需要吧out链表中未传输的数据发送出去即可,所以方法中的参数in为null。这时避免重复执行的方式为:判断in是否为空,因为在ngx_http_writer方法中执行的ngx_http_output_filter方法,in参数均为空。 - 在需要发送响应体时,响应头并不是通过一次调用
ngx_http_output_filter就完成了所有数据的处理,需要调用多次ngx_http_output_filter方法,逐步完成响应的下发。每一次执行ngx_http_output_filter后并不会将ngx_http_writer设置请求的写事件处理,而是将模块本身的处理函数设置为写事件的处理方法,该方法会重复调用ngx_http_output_filter方法来下发需要处理的数据,直到下发的数据完成,再调用ngx_http_finalize_request方法将ngx_http_writer方法设置为写事件的处理方法(这时就可以通过in来避免重复处理了)。在重复调用ngx_http_output_filter方法增加需要传输的数据的时候处理逻辑需要区分模块来判断。对于只应该执行一次处理的模块,可以通过in中最后一个buf中的last_buf来进行判断,该值表示是需要发送的最后一部分数据,那在次之前就可以不进行任何处理,直到最后一部分数据的到来,比如ngx_http_headers_filter_module模块的ngx_http_trailers_filter响应体过滤函数,其处理逻辑即是这样,该模块的方法是在发送响应的最后增加用户指定的内容(add_trailer配置),当日这是应该只能执行一次的方法,这时通过判断last_buf来决定是否需要进行增加响应返回的数据。对于响应整体都需要做操作时,则有更独特的处理逻辑,以ngx_http_gzip_filter_module模块来说,该模块的响应头过滤函数工作是将响应体进行gzip压缩,这时需要对响应体整体进行压缩的,但是不应该在每次有新数据到来时就进行压缩,而是在数据的量级达到指定的大小时再进行压缩,这样该函数并不会直接对ngx_http_output_filter下发的数据立即处理,而是先缓存到该阶段,等积累到指定的大小时,再进行压缩,向之后的请求体过滤函数进行下发。(这时响应方式往往以chunked方式传输)
响应头发送ngx_http_header_filter
在响应头通过响应头fiter链表构建完成后,最终会通过ngx_http_header_filter方法向用户下发响应(ngx_http_header_filter_module模块负责),其处理逻辑如下:
1 | static ngx_str_t ngx_http_status_lines[] = { |
该函数主要是按照之前构建的响应头拼接返回的数据。
响应体发送ngx_http_write_filter
其实说是响应体发送并不完成准确,因为响应头也会使用该方法发送数据。该方法由ngx_http_write_filter_module模块负责,其处理逻辑为:
1 | // 获取需要传输数据字节 |
上面大致分析了请求发送的过程,该函数返回值有三种:
NGX_AGAIN当前下发到该函数的数据还未发送完全,需要后续再次调用该函数下发数据。NGX_OK当前下发到该函数的数据已经完成了发送,但需注意,这里的完成发送并非是说向用户发送的数据一定全部发送完成了,只是到该函数的数据已经发送完成了,如果当前到达该函数的数据只是要发送数据的一部分,后续部分还需要调用该函数来进行数据的下发。NGX_ERROR发送数据出错。
ngx_writer_chain方法
在linux下,上述函数中执行的send_chain为ngx_writev_chain函数,其实现细节如下:
1 | ngx_chain_t * |
关于writev的使用可以参考如下文档:writev。
ngx_http_writer方法
在上文已经介绍过,在最终下发数据时,如果没有一次下发成功,将会设置写事件的处理函数为ngx_http_writer方法(一般是在ngx_http_finalize_request中设置),来继续进行数据的下发,这里详细介绍该方法的执行逻辑:
1 | static void |
请求体处理
对于post请求来说,nginx需要处理其请求体。请求体处理有两种方式,直接丢弃请求体和接收并执行相关操作。选择何种方式来处理请求体往往由模块本身决定。
接收包体时,为防止请求被其他相关操作终止,应当将请求的count加1。再完成接收时,将计数减1。对应丢弃请求体来说,加减均由架构函数完成,对应接收请求来说,加架构完成了,减需要自定义的回调函数来完成。
下面这里对两种方式进行介绍。
相关结构
用于处理请求体的相关结构为ngx_http_request_body_t.
ngx_http_request_body_t
其定义如下:
1 | struct ngx_http_chunked_s { |
接收请求体ngx_http_read_client_request_body
接收客户端请求通过ngx_http_read_client_request_body方法实现,其逻辑如下:
1 | // 参数post_handler为接受完成请求头后处理函数 |
ngx_http_request_body_filter
ngx_http_request_body_filter函数执行接收到的请求体处理。
1 | static ngx_int_t |
ngx_http_request_body_chunked_filter
ngx_http_request_body_chunked_filter为chunked方式下对请求内容的处理。其逻辑如下:
1 | static ngx_int_t |
ngx_http_request_body_length_filter
该函数执行非chunked请求的请求体过滤函数。逻辑如下:
1 | static ngx_int_t |
request_body_no_buffering标志启用读取请求主体的非缓冲模式。 在这种模式下,在调用ngx_http_read_client_request_body之后,bufs链可能仅保留正文的一部分。 要阅读下一部分,需调用ngx_http_read_unbuffered_request_body函数。 返回值NGX_AGAIN和请求标志reading_body表示有更多数据可用。 如果在调用此函数后bufs为NULL,那么此刻没有任何可读的内容。 请求回调read_event_handler将在请求主体的下一部分可用时被调用。
ngx_http_top_request_body_filter
ngx_http_top_request_body_filter方法与请求体和请求头过滤函数类似,可以通过每个模块设置next来串联成一个链表,目前该模块就只有一个函数ngx_http_request_body_save_filter,其逻辑如下:
1 | ngx_int_t |
ngx_chain_update_chains
`该·函数更新链表,释放已经添加到rb->bufs中的链表,用于后续再次接收数据。其逻辑如下:
1 | void |
ngx_http_do_read_client_request_body
该方法执行请求体解析,并且是读请求体时的事件循环,逻辑如下:
1 | static ngx_int_t |
ngx_http_read_client_request_body_handler
ngx_http_read_client_request_body_handler方法是无法一次就完整读取请求体时设置的请求读事件方法,其逻辑如下:
1 | static void |
ngx_http_discard_request_body丢弃请求体
除了需要接收请求体外,可以选择直接丢弃请求体,丢弃不是意味着不接受,而是接收后不做任何处理,直接丢弃。如果不接收请求体,将导致和客户端的连接异常。ngx_http_discard_request_body方法用来接收请求体,其逻辑相比于接收请求体的ngx_http_read_client_request_body方法更简单一些:
1 | ngx_int_t |
这里整体执行逻辑与接收请求体类似,例如ngx_http_read_discarded_request_body对应接收请求体的ngx_http_do_read_client_request_body,ngx_http_discarded_request_body_handler对应ngx_http_read_client_request_body_handler方法,这里不做详细介绍。
结束请求ngx_http_finalize_request
前文很多地方使用了该方法,作为响应结束,这里详细讲解该函数执行逻辑:
1 | void |
上述内容中存在大量子请求相关信息,具体会在代理转发中详细介绍。
ngx_http_finalize_connection
该函数为请求结束,对连接进行处理,主要包括是否需要保持连接,以及对请求体的处理:
1 | static void |
ngx_http_discarded_request_body_handler
该事件处理丢失请求体:
1 | void |
ngx_http_set_keepalive
如果请求是长连接,并且nginx支持长连接,且未达到长连接超时条件,则设置连接为长连接:
1 | static void |
ngx_http_keepalive_handler处理函数
连接处于keepalive时,对应的读事件处理逻辑如下:
1 | static void |
ngx_http_set_lingering_close
对应需要延迟关闭的请求,执行该方法,设置延迟关闭。延迟关闭主要是防止客户端还有下发的数据,而nginx直接关闭套接字,导致向客户端下发的数据没有成功传输完成。参考上面关于延迟关闭配置的解释。
1 | static void |
ngx_http_lingering_close_handler
延迟关闭时读事件的处理函数:
1 | static void |
ngx_http_close_request
该请求关闭当前连接:
1 | static void |
ngx_http_free_request释放请求
1 | void |
ngx_http_terminate_request
在请求出现错误,或者客户端主动关闭时,会执行该函数立即关闭请求。
1 | struct ngx_http_posted_request_s { |
ngx_http_set_write_handler
在结束请求时,如果还有别的阻塞数据还未传输完成,则通过该函数设置对应的写事件处理,确保数据都正常传输到客户端,执行逻辑如下:
1 | static ngx_int_t |
ngx_http_special_response_handler
对于需要返回特殊响应的请求,通过该函数做最后的响应。包括响应大于等于301,或者为201或204的响应。处理逻辑如下:
1 | ngx_int_t |
ngx_http_send_error_page
按照err page配置发送响应。
1 | static ngx_int_t |
ngx_http_internal_redirect内部重定向
该函数执行内部重定向,逻辑如下:
1 | ngx_int_t |
ngx_http_named_location内部命名location
该函数用于执行nginx内部的location重定向,即包含@符号的location配置。逻辑如下:
1 | ngx_int_t |
ngx_http_send_refresh
对应微软浏览器,需要将重定向设置为刷新响应。逻辑如下:
1 | static u_char ngx_http_msie_refresh_head[] = |
ngx_http_send_special_response发送特殊响应
1 | static ngx_int_t |
ngx_http_post_action
post_action配置一般用于统计等信息,即作用是在请求完成之后执行另一个请求。例如配置如下:
1 | server { |
这时,在请求完成/后,会立即执行@add的请求。其实现逻辑为:
1 | static ngx_int_t |
解析配置
初始化核心模块
执行核心模块的ctx->create_conf方法:
1 | for (i = 0; cycle->modules[i]; i++) { |
其中,http核心模块的ctx为:
1 | typedef struct { |
该步骤主要是分配配置存储空间,并为核心模块关注的全局配置赋初值。需要执行的有
ngx_core_module:其返回为
1 | typedef struct { |
ngx_regex_module_ctx,其返回为:
1 | typedef struct { |
配置及参数解析
1 | ngx_memzero(&conf, sizeof(ngx_conf_t)); |
相关结构
ngx_conf_t结构
1 | ngx_conf_s { |
ngx_conf_param函数如下:
1 | char * |
ngx_conf_file_t结构
1 | typedef struct { |
执行的ngx_conf_parse函数如下:
1 | char * |
词法解析(ngx_conf_read_token)
ngx_conf_read_token函数如下:
1 | static ngx_int_t |
默认处理(ngx_conf_handler)
ngx_conf_handler函数如下:
1 | static ngx_int_t |
从上面代码,可以看出来,cycle中的ctx_conf中,并不是每个模块都有一个对应的ctx_conf[modules[i]->index]。一般都是核心模块会存在一个对应的配置。核心模块下的ctx_conf[modules[i]->index]配置,会分配好其管理的每个子模块的存储空间。查找子模块时,通过其所属的核心模块的配置地址,再通过模块的ctx_index查找到对应配置。(具体查找方式较为复杂,详见http模块解析)。
设置配置项解析方式(ngx_commend_S)
下面介绍读取配置时是如何使用ngx_commend_s的:
1 | struct ngx_command_s { |
ngx_str_t name
配置名称,和解析出的名称做比较,确定是否是该模块关注的配置。
ngx_uint_t type
type决定配置项可以在哪些块出现(如http、server、location、if、upstream),以及可以携带参数类型和个数。下表列出了可以的取值。可同时取多个值,通过$ \vert $连接。
| type类型 | type取值 | 含义 |
| 处理配置项时获取当前配置块的方式 | NGX_DIRECT_CONF | 一般由NGX_CORE_MODULE类型的核心模块使用,仅与下面的NGX_MAIN_CONF同时设置,表示模块需要解析不属于任何{}内的全局配置项。它实际上会指定set方法里的第三个参数conf的值,使之指向每个模块解析全局配置项的配置结构体 |
| NGX_ANY_CONF | 当前未使用 | |
| 配置项可以在哪些{}配置块中出现 | NGX_MAIN_CONF | 配置项可以出现在全局配置中,即不属于任何{}配置块 |
| NGX_EVENT_CONF | 配置项可以出现在events{}块内 | |
| NGX_MAIL_MAIN_CONF | 配置项可以出现在mail{}块或imap{}内 | |
| NGX_MAIL_SRV_CONF | 配置项可以出现在server{}块内,但server{}必须在mail{}块或imap{}内 | |
| NGX_HTTP_MAIN_CONF | 配置项可以出现在http{}内 | |
| NGX_HTTP_SRV_CONF | 配置项可以出现在server{}块内,但server{}块必须在http{}内 | |
| NGX_HTTP_SRV_CONF | 配置项可以出现在server{}块内,但server{}块必须在http{}内 | |
| NGX_HTTP_LOC_CONF | 配置项可以出现在location{}块内,但location{}块必须在http{}内 | |
| NGX_HTTP_UPS_CONF | 配置项可以出现在upstream{}块内,但upstream{}块必须在http{}内 | |
| NGX_HTTP_SIF_CONF | 配置项可以出现在server{}块内的if{}中,目前仅rewrite模块使用。if必须属于http{}内 | |
| NGX_HTTP_LIF_CONF | 配置项可以出现在loc{}块内的if{}中,目前仅rewrite模块使用。if必须属于http{}内 | |
| NGX_HTTP_LMT_CONF | 配置项可以出现在limit_except{}内。limit_except必须属于http{}内 | |
| 配置项参数限制 | NGX_CONF_NOARGS | 配置项不携带任何参数 |
| NGX_CONF_TAKE1 | 配置项必须携带1个参数 | |
| NGX_CONF_TAKE2 | 配置项必须携带2个参数 | |
| NGX_CONF_TAKE3 | 配置项必须携带3个参数 | |
| NGX_CONF_TAKE4 | 配置项必须携带4个参数 | |
| NGX_CONF_TAKE5 | 配置项必须携带5个参数 | |
| NGX_CONF_TAKE6 | 配置项必须携带6个参数 | |
| NGX_CONF_TAKE7 | 配置项必须携带7个参数 | |
| NGX_CONF_TAKE12 | 配置项必须携带1~2个参数 | |
| NGX_CONF_TAKE13 | 配置项必须携带1~3个参数 | |
| NGX_CONF_TAKE23 | 配置项必须携带2~3个参数 | |
| NGX_CONF_TAKE123 | 配置项必须携带1~3个参数 | |
| NGX_CONF_TAKE1234 | 配置项必须携带1~4个参数 | |
| 限制配置项后参数出现形式 | NGX_CONF_ARGS_NUMBER | 目前未使用,无意义 |
| NGX_CONF_BLOCK | 配置项定义了一种新的{}块。例如http、server、location等配置,其type必须为NGX_CONF_BLOCK | |
| NGX_CONF_ANY | 不验证配置项携带参数个数 | |
| NGX_CONF_FLAG | 配置项携带参数只能是1个,并且参数只能是on/off | |
| NGX_CONF_1MORE | 配置项携带参数必须超过1个 | |
| NGX_CONF_2MORE | 配置项携带参数必须超过2个 | |
| NGX_CONF_MULTI | 表示当前配置项可以出现在任意块中 |
如果HTTP模块中定义的配置项在nginx.conf配置文件中实际出现的位置和参数格式与type意义不符,那么Nginx启动报错。
每个进程都有一个唯一的ngx_cycle_t核心结构体,其成员conf_ctx维护所有模块配置结构决定配置项可以在哪些块出现决定配置项可以在哪些块出现体。其类型是void。conf_ctx意义为首先指向一个成员皆为指针的数组,其中每个成员指针又指向另外一个成员皆为指针的数组,第二个子数组中的成员指针才会指向个模块生成的配置结构体。这是为了事件模块、http模块、mail模块而设计的。而NGX_CORE_MODULE类型的核心模块解析配置项时,配置项一定是全局的,不会从属任何{}配置块,其不需要这种双数组设计。解析标识为NGX_DIRECT_CONF类型的配置项时,会将void转换为void**。
char(set)(ngx_conf_t cf, ngx_command_t cmd, void *conf)
set回调方法,使用位置在ngx_conf_handler中已展现。对于set方法,我们即可以实现一个回调方法来处理,也可以使用Nginx预设的14个解析配置项方法。预设方法如下:
| 预设方法名 | 行为 |
|---|---|
| ngx_conf_set_flag_slot | 如果nginx.conf文件中某个配置项的参数是on或off(打开或关闭),而且在Nginx模块的代码中使用ngx_flag_t变量来保存这个配置项的参数,就可以将set回调方法设为ngx_conf_set_flag_slot。当nginx.conf文件中参数是on时,代码中的ngx_flag_t类型变量设为1,参数off时为0. |
| ngx_conf_set_str_slot | 如果配置项后只有一个参数,同时在代码中我们希望用ngx_str_t类型变量来报错这个配置项的参数,则可以使用ngx_conf_set_str_slot方法 |
| ngx_conf_set_str_array_slot | 如果配置项会出现多次,每个配置项后面跟着1个参数,而程序中使用一个ngx_array_t动态数组来存储所有参数,且数组中的每个参数都使用ngx_str_t来存储,可以设置该方法。 |
| ngx_conf_set_keyval_slot | 与ngx_conf_set_str_array_slot类似,也是使用ngx_array_t动态数组来存储所有参数。只是每个配置项的参数不再是1个,而必须是2个,且以配置项名 关键字 值的形式出现在nginx.conf中,同时改方法把这些配置项转化为数组,其中每个元素都存储这key/value对。 |
| ngx_conf_set_num_slot | 配置项后必须携带1个参数,且只能是数字,存储这个参数的变量必须是整数 |
| ngx_conf_set_size_slot | 配置项后必须携带1个参数,表示空间大小,可以是一个数字,此时表示字节数(Byte)。如果后面跟着K或k,表示kilobyte,1kb=1024B,如果后面更早m或M,就表示Megabyte,1MB=1024KB。该函数解析后,都转换成byte。 |
| ngx_conf_set_off_slot | 配置项后必须携带1个参数,表示空间上的偏移,可以是一个数字,此时表示字节数(Byte)。如果后面跟着K或k,表示kilobyte,1kb=1024B,如果后面更早m或M,就表示Megabyte,1MB=1024KB。还可以是g或G。该函数解析后,都转换成byte。 |
| ngx_conf_set_msec_slot | 配置项后必须携带1个参数,表示时间。无单位表示秒。m表示分钟。h表示小时。d表示天。w表示周。m表示月(30天)。y表示年。解析后转化为毫秒的单位 |
| ngx_conf_set_sec_slot | 与ngx_conf_set_msec_slot类似,不过解析后转化为秒 |
| ngx_conf_set_bufs_slot | 配置项后必须携带2个参数。第一个参数是数字,第二个参数表示空间大小。例如”gzip-buffers 4 8k”(通常用来表示有多少个ngx_buf_t缓冲区)。第一个不可带单位。第二个为存储大小。该配置对应Nginx最常用的多缓冲区的解决方案(如接收对端发来的TCP流) |
| ngx_conf_set_enum_slot | 配置项后必须携带1个参数,其取值范围是我们设定好的字符串之一。 |
| ngx_conf_set_bitmask_slot | 与ngx_conf_set_enum_slot类似。 |
| ngx_conf_set_access_slot | 这个方法用于设置目录或者文件的读写权限。配置项后可以携带1~3个参数,可以是如下形式:user:rw group:rw all:rw。其意义与Linux上文件或目录的权限一致,但user/group/all后面权限只可以设置rw,或者r |
| ngx_conf_set_path_slot | 用于设置路径,配置项后面必须携带1个参数,表示一个有意义的路径。该方法会把参数转化为ngx_path_t结构 |
ngx_uint_t conf
conf用于指示配置项所处内存的相对偏移位置,仅在type中没有设置NGX_DIRECT_CONF和NGX_MAIN_CONF时才会生效。对于HTTP模块,conf是必须要设置的,其取值范围如下:
| conf在HTTP模块的取值 | 意义 |
|---|---|
| NGX_HTTP_MAIN_CONF_OFFSET | 使用create_main_conf方法产生的结构体来存储解析出的配置项参数 |
| NGX_HTTP_SRV_CONF_OFFSET | 使用create_srv_conf方法产生的结构体来存储解析出的配置项参数 |
| NGX_HTTP_LOC_CONF_OFFSET | 使用create_loc_conf方法产生的结构体来存储解析出的配置项参数 |
HTTP框架可以使用预设的14种方法自动地将解析出的配置项写入HTTP模块代码定义的结构体中,但HTTP模块中可能会定义3个结 构体,分别用于存储main、srv、loc级别的配置项(对应于create_main_conf、 create_srv_conf、create_loc_conf方法创建的结构体),而HTTP框架自动解析时需要知道应把解析出的配置项值写入哪个结构体中,这将由conf成员完成。
对conf的设置是与ngx_http_module_t实现的回调方法相关的。 如果用于存储这个配置项的数据结构是由create_main_conf回调方法完成的,那么必须把conf 设置为NGX_HTTP_MAIN_CONF_OFFSET。同样,如果这个配置项所属的数据结构是由 create_srv_conf回调方法完成的,那么必须把conf设置为NGX_HTTP_SRV_CONF_OFFSET。 可如果create_loc_conf负责生成存储这个配置项的数据结构,就得将conf设置为 NGX_HTTP_LOC_CONF_OFFSET。
目前,功能较为简单的HTTP模块都只实现了create_loc_conf回调方法,对于http{}、 server{}块内出现的同名配置项,都是并入某个location{}内create_loc_conf方法产生的结构体 中的。当我们希望同时出现在http{}、server{}、 location{}块的同名配置项,在HTTP模块的代码中保存于不同的变量中时,就需要实现 create_main_conf方法、create_srv_conf方法产生新的结构体,从而以不同的结构体独立保存 不同级别的配置项,而不是全部合并到某个location下create_loc_conf方法生成的结构体中。
ngx_uint_t offset
offset表示当前配置项在整个存储配置项的结构体中的偏移位置(以字节(Byte)为单位)。在使用Nginx预设的解析配置项方法时,就必须指定offset,这 样Nginx首先通过conf成员找到应该用哪个结构体来存放,然后通过offset成员找到这个结构 体中的相应成员,以便存放该配置。如果是自定义的专用配置项解析方法(只解析某一个配 置项),则可以不设置offset的值。其设置方式主要方式为:
1 |
void *post
post指针有许多用处,其使用方式是在调用set方法内调用。
如果自定义了配置项的回调方法,那么post指针的用途完全由用户来定义。如果不使用 它,那么随意设为NULL即可。如果想将一些数据结构或者方法的指针传过来,那么使用post 也可以。
如果使用Nginx预设的配置项解析方法,就需要根据这些预设方法来决定post的使用方 式。表4-4说明了post相对于14个预设方法的用途。
| pos使用方法 | 适用的预设配置项解析方法 |
| 可以选择是否实现。如果设置NULL,则表示不实现,否则必须实现为指向ngx_conf_post_t结构的指针。ngx_conf_post_t中包含一个方法指针,表示在解析当前配置项完毕后,需要回调这个方法 | ngx_conf_set_flag_slot |
| ngx_conf_set_str_slot | |
| ngx_conf_set_str_array_slot | |
| ngx_conf_set_keyval_slot | |
| ngx_conf_set_num_slot | |
| ngx_conf_set_size_slot | |
| ngx_conf_set_off_slot | |
| ngx_conf_set_msec_slot | |
| ngx_conf_set_sec_slot | |
| 指向ngx_conf_enum_t数组,表示当前配置项的参数必须设置为ngx_conf_enum_t规定的值(类似枚举)。必须定义 | ngx_conf_set_enum_slot |
| 指向ngx_conf_bitmask_t数组,表示当前配置项的参数必须设置为ngx_conf_bitmask_t规定的值(类似枚举)。必须定义 | ngx_conf_set_enum_slot |
| 无任何用处 | ngx_conf_set_buffs_slot |
| ngx_conf_set_path_slot | |
| ngx_conf_set_access_slot |
有9个预设方法在使用post是可以设置为ngx_conf_post_t结构体来使用,其定义如下:
1 | typedef char (ngx_conf_post_handler_pt) (ngx_conf_t cf, void data, void *conf); |
预设配置项处理方法工作原理
1 | char * |
http模块配置解析
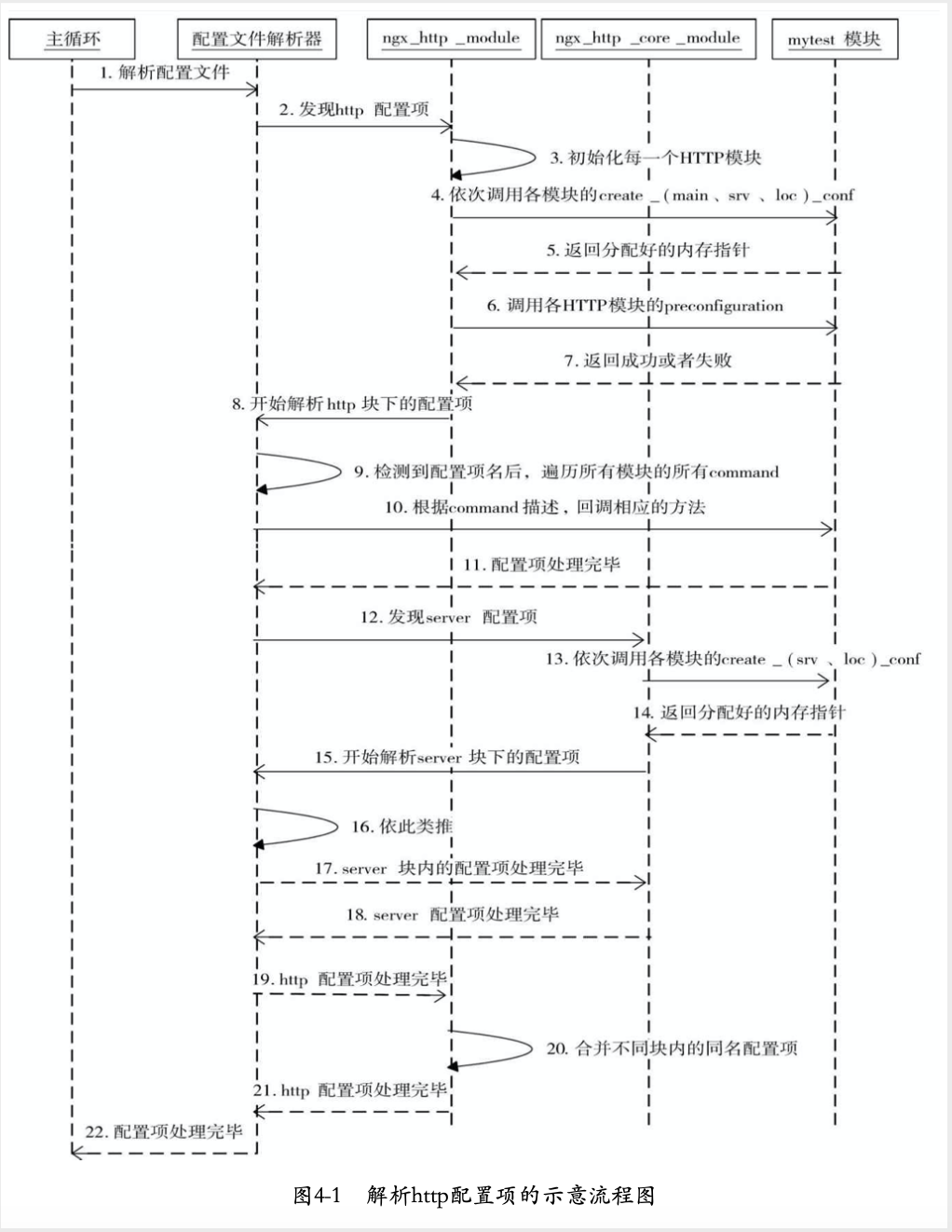
在默认的处理函数ngx_conf_handler中,会会调用核心模块的commands数组的每个元素的set方法。对于http来说,核心模块为
1 | static ngx_command_t ngx_http_commands[] = { |
http层set函数
执行set方法即执行ngx_http_block函数:
1 | static char * |
ngx_http_conf_ctx_t
上面代码中ngx_http_conf_ctx_t类定义如下:
1 | typedef struct { |
分别用来存储main、server、loc块下配置。
ngx_http_core_module模块生成的三个结构
在执行create_main_conf、create_srv_conf、create_loc_conf时,会生成三个结构体,其中ngx_http_core_module是http的核心模块。其生成的三个结构体如下:
ngx_http_core_main_conf_t
1 | typedef struct { |
ngx_http_core_srv_conf_t
1 | typedef struct { |
ngx_http_core_loc_conf_s
1 | struct ngx_http_core_loc_conf_s { |
在处理http块内main配置时,对每个http模块创建了三个结构体,这是为了把同时出现在http、server、location块中相同的配置进行合并而准备的。例如,有一个与server相关的配置(例如负责指定每个TCP连接池大小的connection_pool_size配置项)同时出现在http和server中,那么对其感兴趣的http模块有权决定srv结构内成员究竟是以main级别的为准还是已srv的为准。对loc级别的配置也是如此,loc级别的需要http下创建的loc和server创建的loc和loc级别本身创建的loc三者共同决定。因此main级别的配置会被创建1次(在解析http时创建),server级别的配置会被创建2次(解析http块一次和解析server块一次),loc级别配置会被创建三次(解析http块一次、解析server块一次和解析loc块一次)。具体配置在内存中结构之后会详细解释。
在创建配置后,就会继续解析配置,此时,遇到的第一个http模块就是ngx_http_core_module。从上述代码可以看出来,nginx配置项解析采用的是深度优先搜索模式,其解析的顺序是十分重要的,一定要先解析核心模块,再解析每类模块在该模块下的代理(如http模块的代理为ngx_http_core_module),之后才能再解析该类模块下其他模块。
http级配置解析内存结构
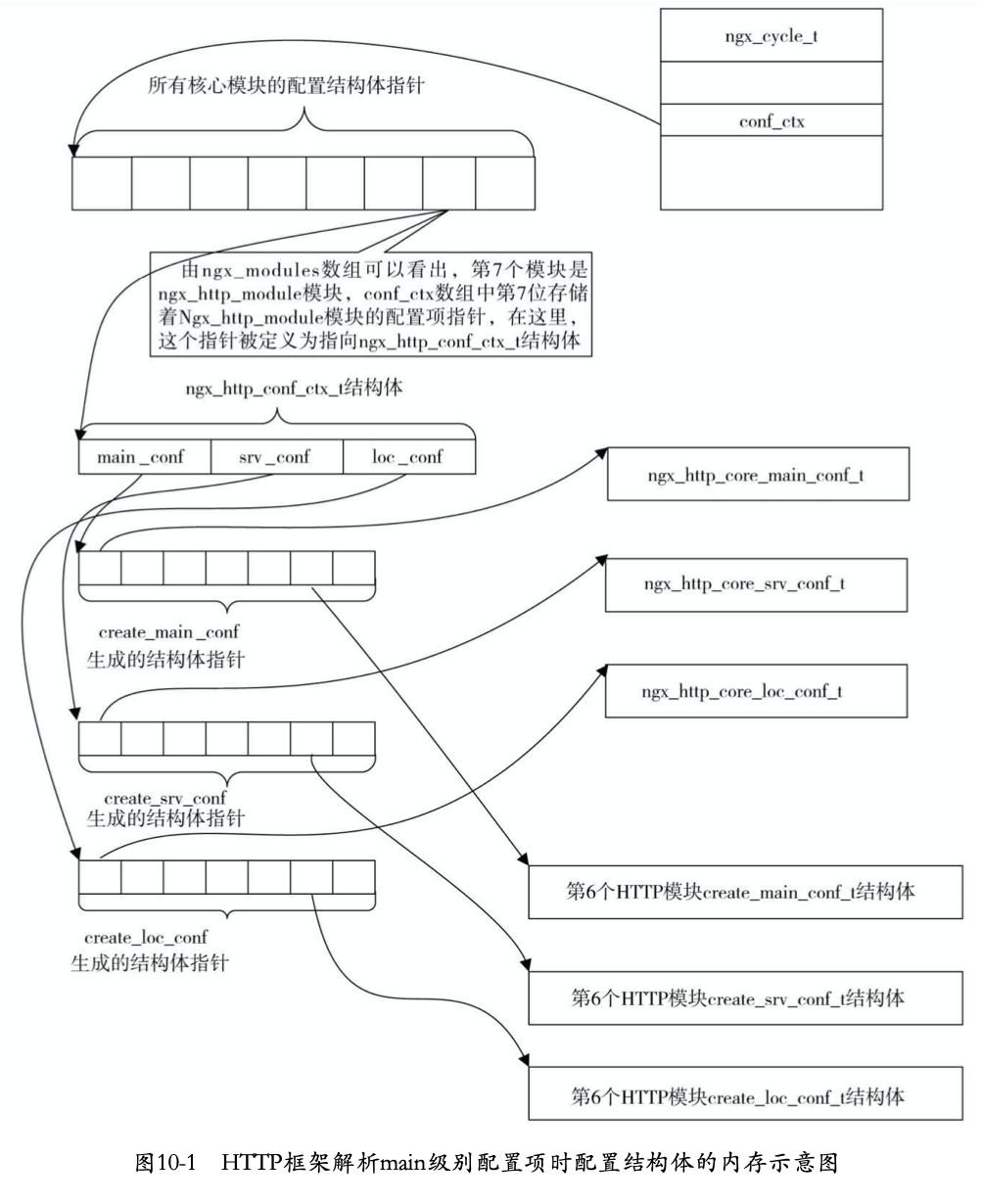
ngx_http_core_module是第一个http模块,其ctx_index为0,因此,数组中第一个指针指向ngx_http_core_module生成的三个结构体。要由ngx_cycle_t获得main级别配置方式如下:
1 | #define ngx_http_get_module_main_conf(r, module) \ |
server级别set函数
在http中,接着执行解析函数时,当解析到server配置时,首先会遇到ngx_http_core_module核心模块的commands中的server。如下:
1 | { ngx_string("server"), |
其函数如下:
1 | static char * |
server级配置解析内存结构
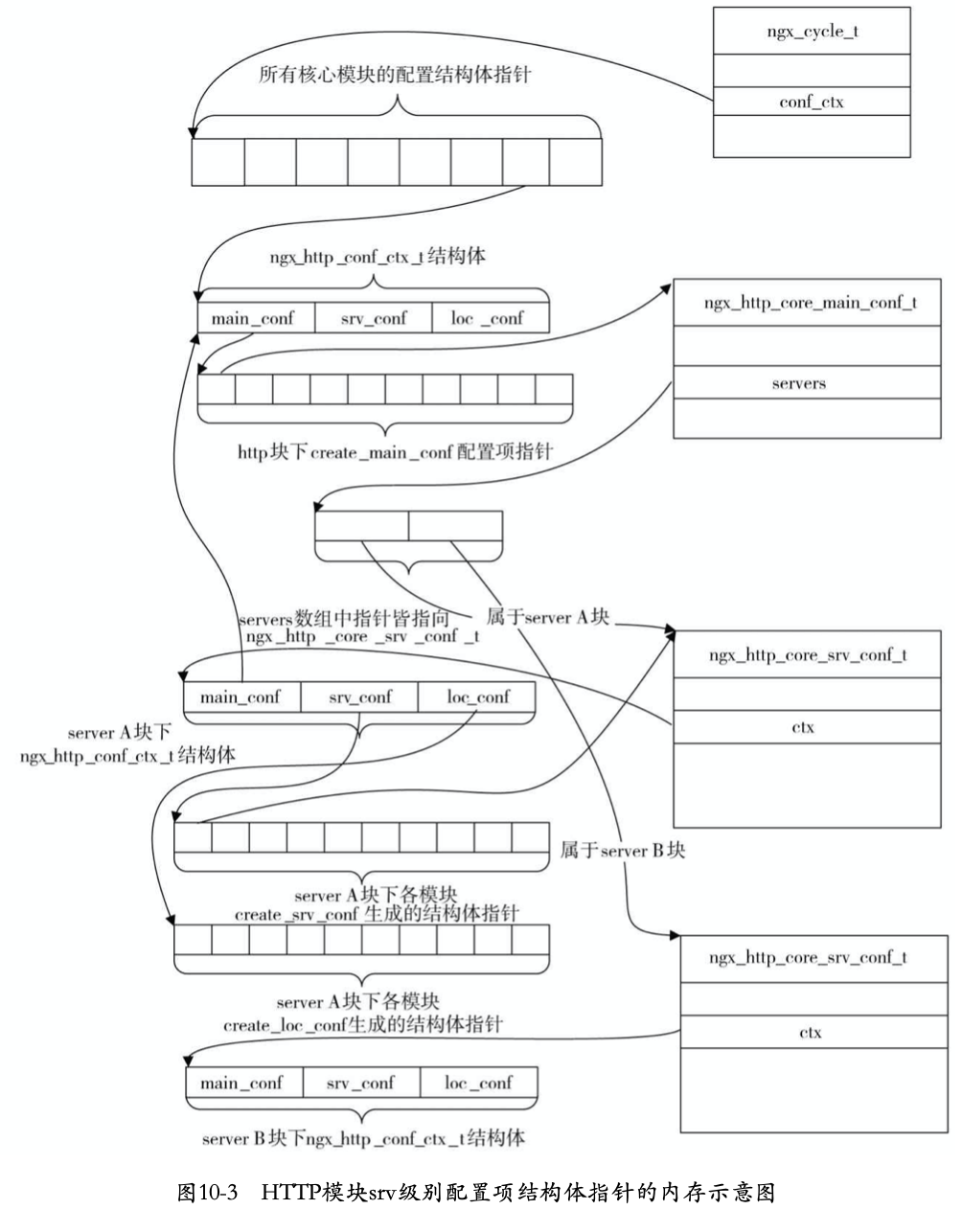
解析每一个server块时都会创建一个新的 ngx_http_conf_ctx_t结构体,其中的main_conf将指向http块下main_conf指针数组,而srv_conf和 loc_conf数组则都会重新分配,它们的内容就是所有HTTP模块的create_srv_conf方法、 create_loc_conf方法创建的结构体指针。
http层的存储结构和server层存储关联方式为:将server层ngx_http_core_module模块生成的ngx_http_core_srv_conf_t添加到main层ngx_http_core_module块生成的ngx_http_core_main_conf_t的server中,其中server层ngx_http_core_module模块生成的ngx_http_core_srv_conf_t中的ctx指向server层生成的ngx_http_conf_ctx_t结构体。使用该方式将main层的配置内存结构和server层配置内存结构串联起来。
管理监听端口号
nginx配置,使用listen来设置监听端口:
1 | listen address:port [default(deprecated in 0.8.21) | default_server | [backlog=num | rcvbuf=size | sndbuf=size | accept_filter=filter | deferred | bind | ipv6only=[on|off] ssl | so_keepalive=on|off|[keepidle]:[keepintvl]:[keepcnt]]]; |
listen决定nginx服务监听端口。listen后可以加IP地址、端口号或者主机名。如
1 | listen 127.0.0.1:8002; |
地址后可以加其他参数。
| 参数 | 含义 |
|---|---|
| default | 将所在server块作为整个web服务的默认server块。当一个请求无法匹配配置文件中的所有主机域名时,就会选择默认虚拟主机。如果所有server都未指定,则默认选第一个。 |
| backlog=num | TCP中backlog大小。(默认-1,无限制)在TCP建立三次连接时,进程还未监听句柄,此时backlog队列将会放置这些连接。如果backlog已满,还有客户端企图建立连接,则会失败。 |
| rcvbuf=size | 设置监听句柄的SO_RCVBUF参数。 |
| sndbuf=size | 设置监听句柄的SO_SNDBUF参数。 |
| accept_filter | 设置accept过滤,只对FreeBSD系统有用。 |
| deferred | 设置该参数时,若用户建立了TCP连接(三次握手),内核也不会对该连接调度worker进程来处理,只会在用户真正发送请求时才会分配worker进程。使用于大并发情况下。 |
| bind | 绑定当前端口/地址对,如127.0.0.1:8000。 |
| ssl | 在当前监听的端口上建立的连接必须基于SSL。 |
| so_keepalive | 当客户端与服务器端三次握手正式建立tcp以后,默认情况下,除非客户端或服务器端关闭上层socket,否则tcp会始终保持连接,如果这个时候网络断掉,这个链接就会变成一个死链接,会占用服务器资源。解决方式为:大多数的上游应用会通过心跳机制来检测对方是否存活,不存会则由上游应用程序关闭socket释放链接。对于tcp探活来说,存在三个参数:tcp_keepalive_time(tcp建立链接后指定时间无数据传输,则会发出探活数据包)、tcp_keepalive_probes(发出探活数据包次数)、tcp_keepalive_intvl(探活数据包之间间隔时间)so_keepalive=on 表示开启tcp探活,并且使用系统内核的参数。so_keepalive=30m::10 表示开启tcp探活,30分钟后伍数据会发送探活包,时间间隔使用系统默认的,发送10次探活包。 |
| fastopen | number,HTTP 处于保持连接(keepalive)状态时,允许不经过三次握手的 TCP 连接的队列的最大数 |
| sentfib | number,为监听套接字设置关联路由表,仅在 FreeBSD 系统上有效 |
| ipv6only | on,只接收 IPv6 连接或接收 IPv6 和 IPv4 连接 |
| reuseport | 默认情况下,所有的工作进程会共享一个 socket 去监听同一 IP 和端口的组合。该参数启用后,允许每个工作进程有独立的 socket 去监听同一 IP 和端口的组合,内核会对传人的连接进行负载均衡。 |
| proxy_protocol | 在指定监听端口上启用 proxy_protocol 协议支持 |
解析时,其属于ngx_http_core_commands,具体如下:
1 | { ngx_string("listen"), |
对应相关数据结构
ngx_http_listen_opt_t
1 | typedef struct { |
ngx_url_t
该结构是用于存储解析url后的结果信息的:
1 | typedef struct { |
ngx_http_conf_port_t
该类是记录端口号对应每一个地址的结构。(由于一个机器可能存在多个ip地址)
1 | typedef struct { |
其中ngx_http_core_main_conf_t中的ports参数的成员即是ngx_http_conf_port_t。
ngx_http_conf_addr_t
由于一个端口,我们可以同时监听多个ip(一个机器可能存在多个ip地址)。nginx使用ngx_http_conf_addr_t结构来表示一个对应着具体地址的监听端口,因此一个ngx_http_conf_port_t可能对应多个ngx_http_conf_addr_t。具体结构如下:
1 | typedef struct { |
监听端口与server{}虚拟主机间内存关系
对于一个如下的配置:
1 | http { |
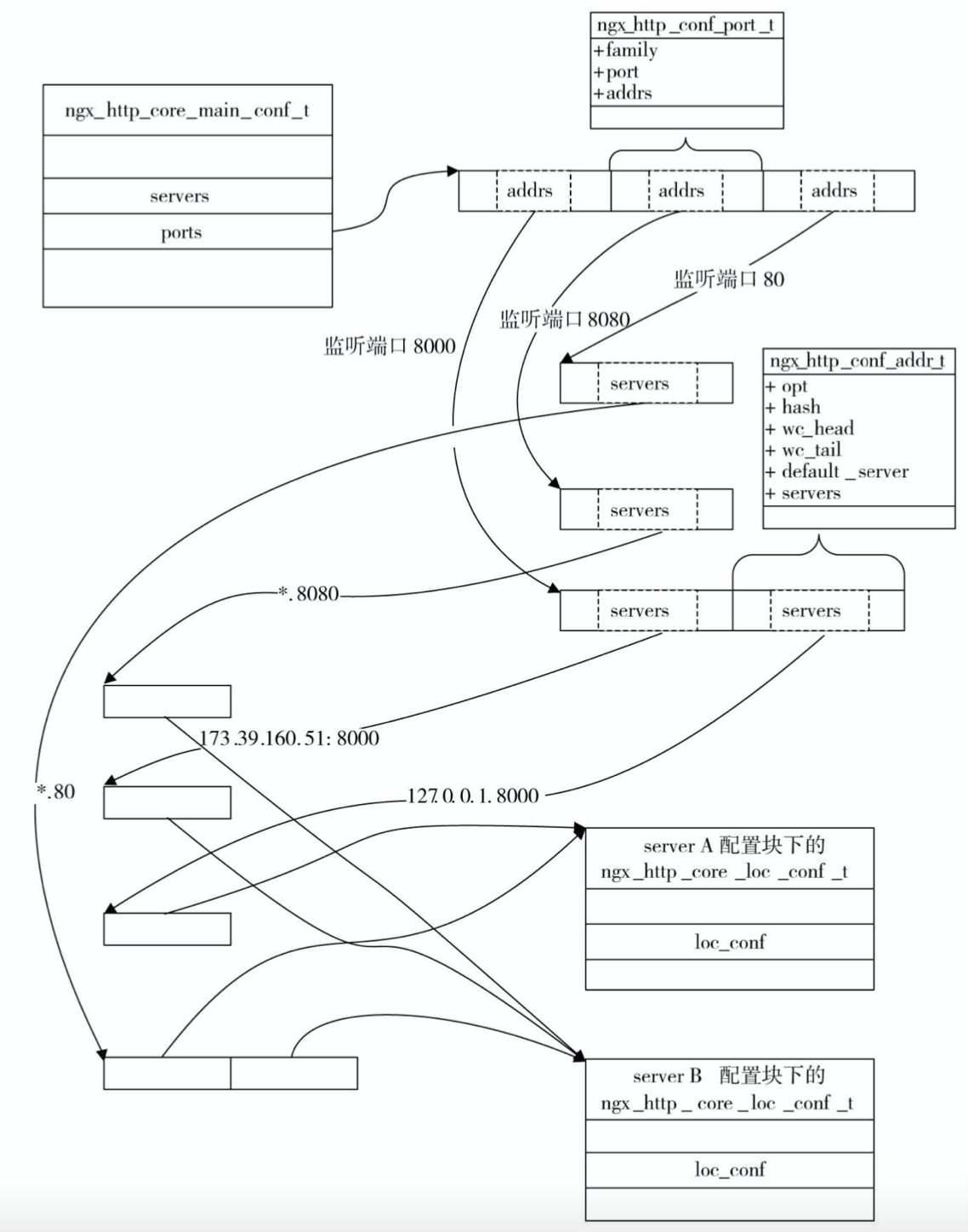
set方法
ngx_http_core_listen
其中对应的ngx_http_core_listen方法如下:
1 | static char * |
这里需要着重介绍一下bind标志位。bind表示是否一个ip+port的地址进行绑定。这样的目的是,如果在一个在同样的端口上,存在一个通配符形式地址(即任意ip地址)时。对于bind的地址来说,会先开启一个地址的监听,让bind的端口走单独的监听,其他未绑定的地址走通配符监听。这样主要是因为我们可能希望在该bind的地址上设置一些额外信息,如backlog、rcvbuf、sndbuf等内容。因此在设置这些额外参数时,就会默认将该地址设置为bind。当然也可以通过配置中直接设置bind的方式指明需要单独进行监听。
解析url
ngx_parse_url
解析参数的代码如下:
1 | ngx_int_t |
这里使用的是ngx_parse_inet_url函数。具体逻辑如下:
1 | static ngx_int_t |
ngx_inet_add_addr
该方法用于将ngx_url_t解析出的地址添加到其addrs参数中。具体逻辑如下:
1 | static ngx_int_t |
ngx_inet_resolve_host
该方法将域名解析为ip地址。使用的方法为getaddrinfo函数。具体可以参考地址查询
代码逻辑如下:
1 | ngx_int_t |
这里配置的主机可以任意配置,在设置监听时,如果解析出的ip地址不是机器表示的ip,则报错。
添加监听地址到ports中
ngx_http_add_listen
1 | ngx_int_t |
ngx_http_add_address
1 | static ngx_int_t |
gx_http_add_server
绑定ip+port形式的地址到对应的server块中。逻辑如下:
1 | static ngx_int_t |
ngx_http_add_addresses
当监听端口(port形式的地址)已经存在一个ngx_http_conf_port_t结构时,这时添加一个addr(ip+port形式的地址)需要使用该方法。该方法会先对比是否已存在对应的ip+port形式的地址,再进行相应操作。具体逻辑如下:
1 | static ngx_int_t |
server_name处理
快速查找请求对应的server块和server_name密切相关,这里先来看一下配置中server_name相应的处理。注意一个server块支持多个server_name,且server_name支持精确名,通配符和正则表达式。在未设置时,默认为空。
相关数据结构
ngx_http_server_name_t
ngx_http_server_name_t结构用户存储服务名,并构建服务名到server的关系
1 | typedef struct { |
处理逻辑
1 | { ngx_string("server_name"), |
1 | static char * |
注意,对应某个模块的serve_name未明确配置来说,其对应的ngx_http_core_srv_conf_t的server_names中将为空。
server块的快速查找
相关数据结构
相关数据结构可以先不看,先看处理函数,当遇到对应结构时再查看。
ngx_http_port_t
每个监听地址实际对应的地址数量和具体每个地址信息。由于含有通配符的地址,可能只需要进行一个监听,但对应多个地址。
1 | typedef struct { |
ngx_listening_t
前文已介绍过。
ngx_http_in_addr_t
1 | typedef struct { |
ngx_http_addr_conf_s
1 | struct ngx_http_addr_conf_s { |
ngx_http_virtual_names_t
1 | typedef struct { |
ngx_http_optimize_servers
经过上述的set方法,已经构建了从main级别的ngx_http_core_main_conf_t成员ports(ngx_http_conf_port_t,port形式的地址)数组、到addrs(ngx_http_conf_addr_t,ip+port形式的地址)、再到servers(ngx_http_core_srv_conf_t,每一个虚拟server)数组的关系。但每次查找时,使用ip+port的地址,再查找对应的server是相对复杂的,如果有大量的server块,并且监听的是同一个ip+port形式的地址。这时逐个进行server_name和请求的host匹配是过于缓慢的。为了加速查找,这里在ip+port形式的地址中,增加了hash表。已加速查找。具体hash表的构建在http层set函数ngx_http_block的ngx_http_optimize_servers方法中。其逻辑如下:
1 | /* optimize the lists of ports, addresses and server names */ |
1 | static ngx_int_t |
ngx_http_server_names
1 | static ngx_int_t |
ngx_http_init_listening
1 | static ngx_int_t |
ngx_http_add_listening
1 | static ngx_listening_t * |
ngx_http_add_addrs
ipv4和ipv6对应的处理类似,这里以ipv4举例:
1 | static ngx_int_t |
location层set函数
在server中,接着执行解析函数时,当解析到location配置时,首先会遇到ngx_http_core_module核心模块的commands中的location。如下:
1 | { ngx_string("location"), |
其函数如下:
1 | static char * |
loc级配置解析内存结构
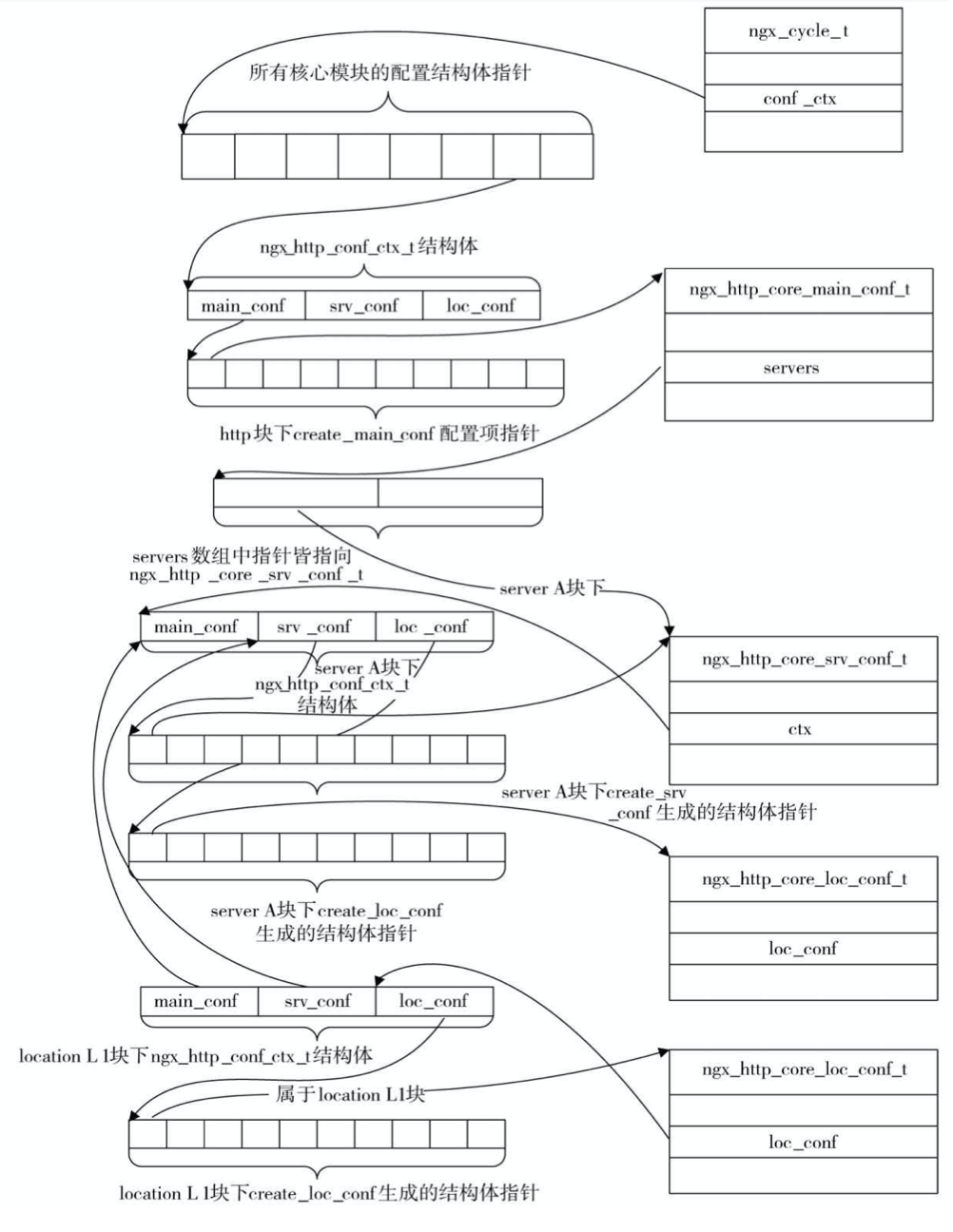
解析每一个location块时都会创建一个新的 ngx_http_conf_ctx_t结构体,其中的main_conf、srv_conf将指向http块下main_conf、srv_conf指针数组,loc_conf数组则都会重新分配,内容就是所有HTTP模块的create_loc_conf方法创建的结构体指针。
server层的存储结构和location层存储关联方式为:将location层ngx_http_core_module模块生成的ngx_http_core_loc_conf_s添加到server层ngx_http_core_module块生成的ngx_http_core_loc_conf_s的locations中,ngx_http_core_loc_conf_s的locations为一个队列,其元素为ngx_http_location_queue_t。定义如下:
1 | typedef struct { |
使用ngx_http_location_queue_t将server层配置与location层配置相关联,server层的ngx_http_core_loc_conf_s的locations存储了其下所有location块生成的ngx_http_location_queue_t。最终解析后结构可能如下:
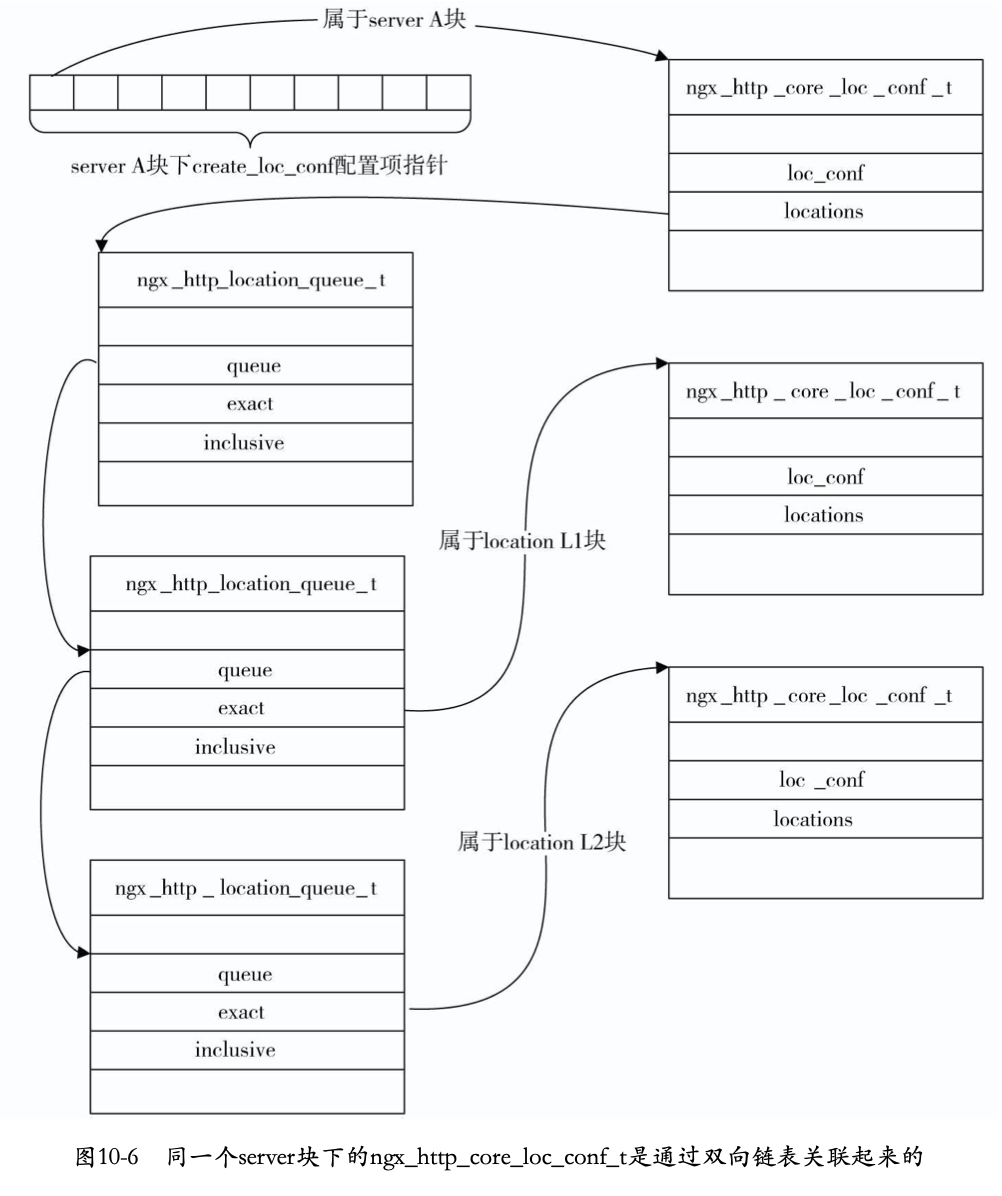
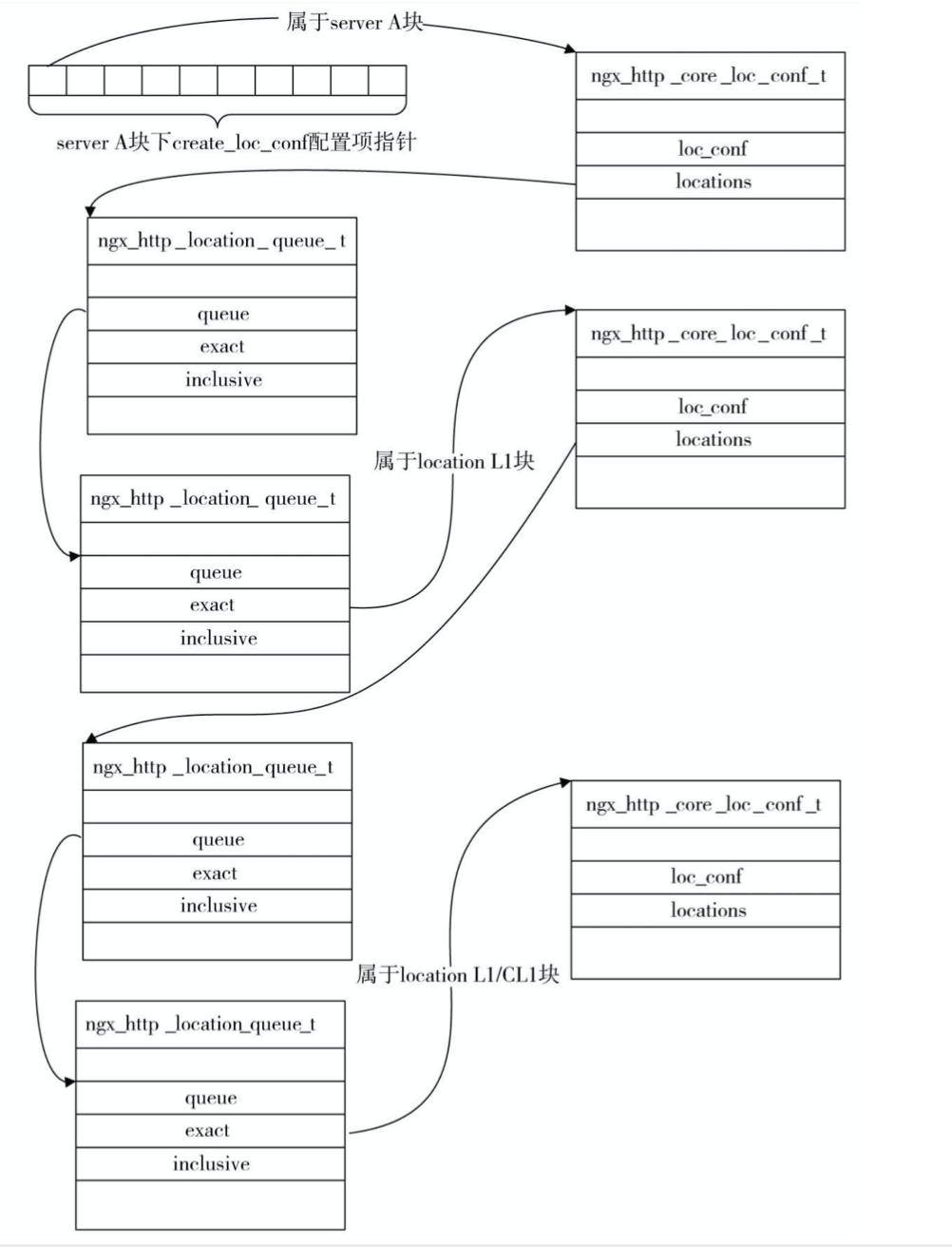
location本身是可以进行嵌套的,嵌套后结构也是可以按照上面的方式进行扩招,即上一层的ngx_http_core_loc_conf_s中的locations存储下一层的所有location解析。例如:
1 | http { |
其解析结果为:
向locations中增加ngx_http_core_loc_conf_t的代码如下:
1 | ngx_int_t |
从上述代码可以看出来,locations并非直接存储的ngx_http_location_queue_t。而是一个ngx_queue_t,即nginx自己实现的双向队列。这里存储的是ngx_http_location_queue_t结构中的queue队列,可以通过ngx_queue_t支持的操作,获取到对应的源数据。
正则表达式解析
配置项合并
合并配置项,主要是合并main层的srv_conf与server层的srv_conf合并,以及main层的loc_conf与server层的loc_conf和location层的loc_conf三者之间的合并。即如下图:
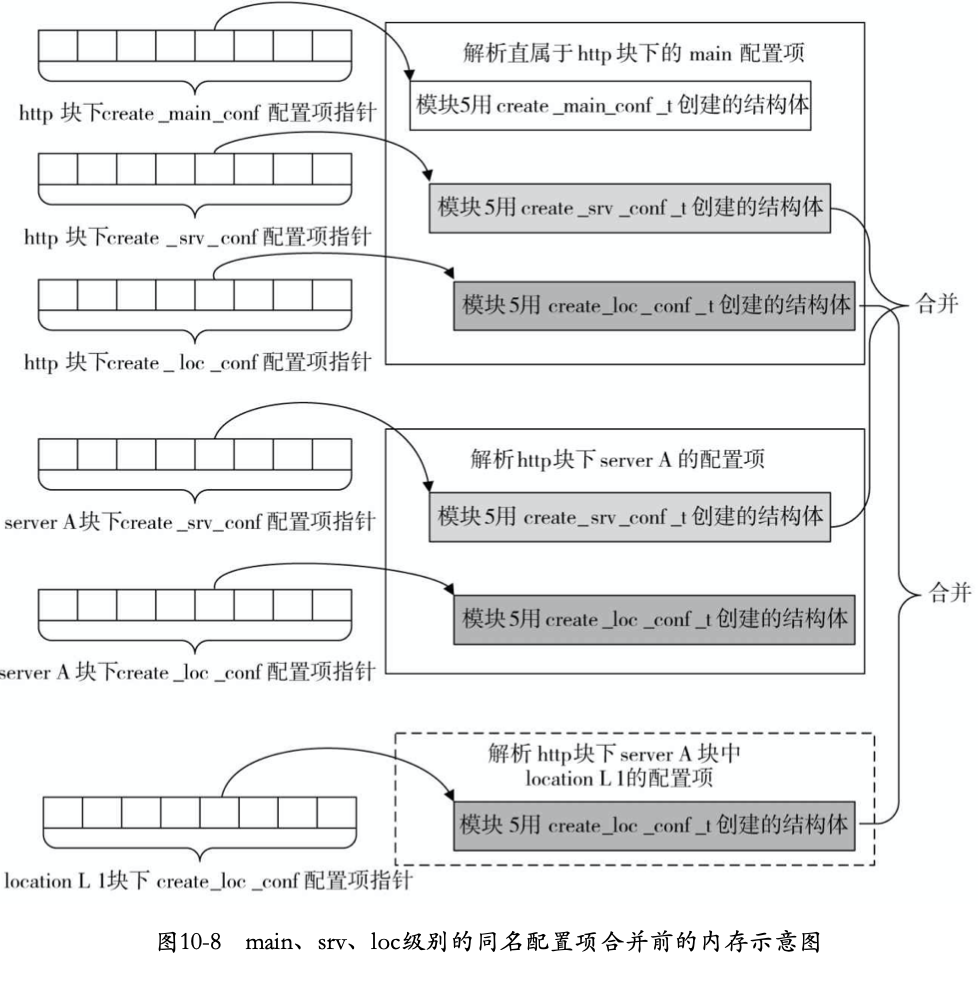
在http层解析完成配置后,就会进行配置项的合并:
1 | // 获取http级别ngx_http_core_module创建的http_ngx_core_main_conf_t |
ngx_http_merge_servers
1 | static char * |
ngx_http_merge_locations
1 | static char * |
创建location配置树
当请求到达时,需要先找到对应的server模块,再根据请求的uri找到对应的location配置块。location存储在server层级创建的ngx_http_core_loc_conf_s的locations,使用双向链表存储,这时查找效率太慢,因此为了加速查询,构建一个快速查询的树结构。其代码在http层set函数ngx_http_block。
1 | /* create location trees */ |
locations排序和分隔ngx_http_init_locations:
1 | static ngx_int_t |
对exact_match 或 inclusive类型的location构建静态树:
1 | static ngx_int_t |
融合exact和inclusive类型的location代码:
1 | static ngx_int_t |
构架前缀列表ngx_http_create_locations_list:
1 | static void |
例如,对于如下的location配置:
1 | location ^~ /abc |
则经过ngx_http_create_locations_list后,locations结构如下:
1 | /abc ---> /bef ---> /bef/hl ---> /efg ---> /fgk |
构建静态树ngx_http_create_locations_tree:
1 | static ngx_http_location_tree_node_t * |
构建出的ngx_http_location_tree_node_t结构为:
1 | struct ngx_http_location_tree_node_s { |
http头初始化
1 | if (ngx_http_init_headers_in_hash(cf, cmcf) != NGX_OK) { |
对于每一个http头会对应到一个结构体:
1 | typedef struct { |
其中handler为请求中存在该头时的处理函数。
1 | static ngx_int_t |
处理阶段
main级别创建的ngx_http_core_main_conf_t的phases字段管理http处理阶段:
1 | typedef struct { |
每一个阶段对应一个函数列表,每个阶段执行时,依次执行。
存在如下阶段:
1 | typedef enum { |
有些阶段是必须的,有些阶段是可选的。上述11个阶段中NGX_HTTP_FIND_CONFIG_PHASE、NGX_HTTP_POST_REWRITE_PHASE、NGX_HTTP_POST_ACCESS_PHASE三个阶段不允许http模块加入增加的ngx_http_handler_pt方法处理用户请求,其仅由http框架实现。
初始化处理阶段
1 | // 初始化处理阶段 |
ngx_http_init_phases方法会初始化必须的处理阶段到main级别创建的ngx_http_core_main_conf_t中的phases中。其中phases是一个存储每个阶段处理函数的临时变量。处理方法如下:
1 | static ngx_int_t |
在http初始化过程中,任何HTTP模块都可以在postconfiguration中增加自定义的方法到phases中某个阶段的数组中。
例如:ngx_http_index_module模块的postconfiguration方法ngx_http_index_init会添加NGX_HTTP_CONTENT_PHASE阶段处理方法:
1 | static ngx_int_t |
默认的NGX_HTTP_CONTENT_PHASE由ngx_http_static_module模块添加。
请求处理阶段
phases只是临时存储请求阶段,真正请求时,使用的是phase_engine字段。先看一下其结构:
1 | typedef struct { |
在经过初始化处理阶段后,就会执行ngx_http_init_phase_handlers方法来确定阶段执行顺序。
1 | static ngx_int_t |
每个阶段的checker函数
核心模块收尾
在执行完子模块的解析后,会执行核心模块的ctx的init_conf方法。其执行顺序完成ngx_conf_parse函数后,其代码如下:
1 | for (i = 0; cycle->modules[i]; i++) { |
这里执行核心模块的init_conf,对核心模块所关系的内容,根据之前的解析,进行完整的赋值。
因此各个模块到此,其解析过程为:
- 首先执行核心模块的ctx成员的create_conf方法。
- 在每个核心模块中,执行其管理的模块的create_*_conf类(如create_conf,create_main_conf,preconfiguration)方法。
- 在每个核心模块中,执行其管理的模块的ini_*_conf类(如init_conf,init_main_conf,merge_srv_conf,merge_loc_conf)方法。
- 最后执行核心模块的ctx成员的create_conf方法。
事件模块
解析配置
在linux下,默认的事件模块包含如下三部分:
1 | ngx_module_t *ngx_modules[] = { |
ngx_events_module模块
其内容如下:
1 | static ngx_command_t ngx_events_commands[] = { |
其不存在module的create_conf方法。只存在init_conf方法。
因此其执行顺序为:ngx_events_commands指定的配置解析->init_conf。这两步均在init_cycle函数中执行。
comands数组处理函数
envents:ngx_events_block
执行模块的commands时执行函数:
1 | static char * |
ctx的init_conf:ngx_event_init_conf
在执行完成所有事件配置解析后,会调用核心事件模块ngx_envents_module的init_conf方法,其处理逻辑如下:
1 | static char * |
复制监听地址的逻辑如下:
1 | ngx_int_t |
注意,执行核心module的init_conf在打开监听套接字之前,即克隆监听套接字也是在实际监听之前。
ngx_event_core_module模块
ngx_event_core_module模块为事件模块的核心模块。其定义如下:
1 | static ngx_str_t event_core_name = ngx_string("event_core"); |
相关数据结构
ngx_event_module_t
ngx_event_module_t为事件模块(非核心模块)的ctx执行的结构体,其定义如下:
1 | typedef struct { |
其中ngx_event_actions_t定义如下:
1 | typedef struct { |
ngx_event_conf_t
该类为ngx_event_core_module在conf_ctx中构建的结构体,其定义如下:
1 | typedef struct { |
ctx的create_conf函数:ngx_event_core_create_conf
其逻辑如下:
1 | static void * |
comands中对应配置的处理
这里只介绍非通用的方法,对于系统定义的一些通用解析配置方式,可参考配置解析一章中的详细说明。
worker_connections配置解析方法
1 | static char * |
use配置解析方法
1 | static char * |
debug_connections配置解析方法
ctx的init_conf函数:ngx_event_core_init_conf
在执行完成commands方法后,会运行ctx的init_conf方法,对ngx_event_conf_t完成初始化。其方法如下:
1 | static char * |
module的init_module方法
在执行完成配置解析后,在init_cycle初始化cycle的结尾(关闭无用资源前)会执行每个模块的init_module方法(在进入worker子进程前)。事件核心模块具有该方法,其逻辑如下:
1 | static ngx_int_t |
关于进程资源限制的内容可以查看如下文档:进程资源信息。
module的init_process方法
在启动worker子进程后,会先执行相应的初始化工作,这时会调用所有模块的init_process方法。事件核心模块的该方法执行逻辑如下:这部分的代码涉及后续的内容较多,可以先查阅本章的事件处理。
1 | static ngx_int_t |
ngx_epoll_module模块
1 | static ngx_str_t epoll_name = ngx_string("epoll"); |
相关结构
ngx_epoll_conf_t
该结构存储关于事件驱动和文件异步I/O的配置内容。
1 | typedef struct { |
对其设置较为简单,都是调用系统通过的解析方法,这里就不做过多介绍了。
ctx的create_conf方法
1 | static void * |
ctx的init_conf方法
1 | static char * |
系统接口
事件处理主要涉及两个功能,一个是网络事件的epoll模块,一个是文件异步I/O模块。这里先对这两个功能在linux下如何使用进行介绍,再来看nginx如果使用。
epoll事件驱动
epoll特点
讨论epoll事件驱动的特点,要先来讨论一下select和poll的问题。
- select由于传参是最大的套接字值,因此其限制监听的套接字数量。
- select和poll在收集事件时,将所有连接的套接字传递给内核(大量内存负责),内核遍历寻找这些连接上是否存在未处理的事件(复杂度O(n))。
由于以上两个特性,导致select和poll事件驱动不适合处理高并发连接的情况。因此在2.6以后的linux内核支持了epoll事件驱动。很好的解决了上述问题。
对于第一个问题:用户态到内核态大量拷贝操作,epoll解决方式是:使用mmap内存映射,将内核态和用户态使用的内存统一,避免拷贝操作。
对于第二个问题:内核需要遍历所有连接,epoll解决方案是,对于每个连接,都会与设备(如网卡)驱动程序建立回调关系,即,相应的事件发送时会调用这里的回调方案。这个回调方法内核中叫做ep_poll_callback。回调方法会将触发的事件添加到一个链表中,在我们获取已经触发的事件时,直接返回链表即可,不用再进行遍历。
epoll使用
epoll只提供了三个函数,让我们来进行事件处理。
epoll_create
1 | int epoll_create(int size); |
epoll_create返回一个句柄,之后epoll的使用都依赖该句柄来标识。size是告诉epoll所处理的大致事件数目。不再使用epoll时,需要调用close关闭这个句柄。size参数只是告诉内核这个epoll对象会处理的事件的大致数目,而不是能够处理的事件的最大个数。新版的Linux内核版本中size已无意义。
epoll_ctl
1 | int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event); |
epoll_ctl向epoll对象中添加、修改或者删除感兴趣的事件,成功返回0,否则返回-1,此时需要根据errno错误码判断错误类型。epoll_wait方法返回的事件必然是通过epoll_ctl添加到epoll中的。参数epfd是epoll_create创建的句柄。op对应操作类型,取值如下:
| op取值 | 含义 |
|---|---|
| EPOLL_CLT_ADD | 添加新的事件到epoll中 |
| EPOLL_CLT_MOD | 修改epoll中的事件 |
| EPOLL_CLT_DEL | 删除epoll中的事件 |
第三个参数fd是待检测的连接套接字。
第四个参数告诉epoll对什么样的事件感兴趣,其使用的是epoll_event结构体。epoll_event定义如下:
1 | struct epoll_event { |
其中event表示感兴趣事件,取值如下:
| events取值 | 含义 |
|---|---|
| EPOLLIN | 表示对应的连接上有数据可读(TCP连接的远端主动关闭事件,也相当于可读事件,因为需要处理发送来的FIN包。对应监听端口,远端发送来连接请求,也是可读事件,之后调用accept) |
| EPOLLOUT | 表示对应连接上可以写入数据发送(主动向上游服务器发起非阻塞的TCP连接,连接建立成功的事件相当于可写事件) |
| EPOLLRDHUP | 表示TCP连接的远端关闭或者半关闭连接 |
| EPOLLPRI | 表示对应的连接上有紧急数据要读 |
| EPOLLERR | 表示对应的连接发生错误 |
| EPOLLHUP | 表示对应的连接被挂起 |
| EPOLLET | 表示将触发方式设置为边缘触发(ET),系统默认为水平触发(LT) |
| EPOLLONESHOT | 表示对事件只处理一次,下次需要处理时需要重新加入epoll |
data成员是一个epoll_data联合,其定义如下:
1 | struct union epoll_data{ |
可以看出,data成员与具体的使用方式有关。例如,ngx_epoll_module模块只使用了联合的ptr成员,作为指向ngx_connection_t连接的指针。
epoll_wait
1 | int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout) |
收集epoll监控的事件中已经发生的事件,如果没有事件发生,则最多等待timeout秒返回。epoll_wait返回值表示当前发生的事件个数,如果返回0,表示本次调用中没有事件发生,如果返回-1,则表示错误,需要检查errno错误码来判断错误类型。第一个参数epfd为epoll的描述符。第二个参数events是分配好的epoll_event结构体数组,epoll将会把发生的事件复制到events数组中(events不能是空指针,内核只负责复制数据到events,不会帮助用户在用户态中分配内存。)第三个参数是maxevents表示本次可以返回的最大事件数目,通常maxevents参数与预分配的events数组的大小一致。timeout为-1表示一直阻塞,直到有事件触发。
epoll原理
介绍完epoll如何使用,这里再简单介绍一下epoll的原理。
在调用epoll_create时,Linux内核会创建一个eventpoll的结构体,其中有两个成员与epoll的使用方式密切相关。
1 | struct eventpoll { |
每个epoll对象都有一个独立的eventpoll结构体,这个结构体会在内核空间中创造独立的内存,用于存储使用epoll_ctl方法向epoll对象中添加进来的事件。这些事件会被挂到rbr红黑树中,以支持快速的增加、删除、变更。rbr的红黑树和前文描述的nginx构建的红黑树类似。
所有添加到epoll中的事件都会与设备(如网卡)驱动程序建立回调关系,即相应事件发生时会调用这里的回调方法。这个回调方法在内核中叫做ep_poll_callback,它会把这样的事件放到rdllist双线链表中。rdllist双向链表与前文nginx创建的双向链表几乎一致。
在epoll中,对每个事件都会建立一个epitem结构体:
1 | struct epitem { |
epitem包含每一个事件对应着的信息。
当调用epoll_wait检查是否有事件发生时,只是检查eventpoll对象中的rdllist双向链表是否有epitem元素而已。
epoll有两种工作模式:LT(水平触发)模式和ET(边缘触发)模式。默认情况下,epoll采用LT模式工作,这时可以处理阻塞和非阻塞套接字。而在epoll_ctl中的EPOLLET表明可以将一个事件改为ET模式,ET模式效率更高,其只能处理非阻塞套接字。ET模式和LT模式主要区别在于:当一个事件到来时,ET模式下从epoll_wait调用中获取到这个事件后,如果这次没有把事件对应的套接字缓冲区处理完,在这个套接字没有新的事件再次到来时,ET模式下无法再次从epoll_wait中获取到这个事件,而LT模式可以。因此在LT模式下开发基于epoll的应用要简单一些,不太容易出错,而在ET模式下事件发生时,如果没有彻底将缓冲区数据处理完全,会导致缓冲区中的用户请求得不到响应。默认情况下,nginx通过ET模式使用epoll。
文件异步I/O
epoll解决了网络事件的事件驱动。这里介绍一下Linux内核2.6.2x之后版本中支持的文件异步I/O操作。这里提到的文件异步I/O不是glibc库提供的文件异步io。glibc提供的文件异步I/O是基于多线程实现的,不是真正意义的异步I/O。这里说的文件异步I/O是由Linux内核实现,只有在内核完成了磁盘操作,内核才会通知进程,进而使得磁盘文件的处理与网络事件一样高效。
使用Linux内核版本的文件异步I/O前提是内核版本必须支持文件异步I/O。这样的好处是,nginx把读文件的操作异步地提交给内核后,内核会通知I/O设备独立执行操作,这样nginx进程可以继续充分利用cpu。当大量读事件堆积到I/O设备的队列中时,将会发挥出内核中电梯算法的优势,从而降低随机读取磁盘扇区的成本。
Linux内核级别的文件异步I/O是不支持缓存操作的,即,即使要操作的文件快在Linux文件缓存中,也不会通过读取、更改缓存中的文件块来代替实际对磁盘的操作。使用文件异步I/O虽然从阻塞worker进程的角度来说有很大好转,但对单个请求来说,有可能降低处理速度的,因为原本可以从内存中快速获取的文件块在使用了文件异步I/O后必须通过磁盘获取。如果大部分用户请求对文件的操作都会落到文件缓存中,那么就不应该使用异步I/O。
目前nginx仅支持在读文件时使用异步I/O,因为在写入文件时,往往是写入内存中就立即返回,速度很快,使用异步I/O反而会速度下降。
nginx默认不使用文件异步I/O,要向使用,则在执行config时,增加参数:
1 | ./configure --with-file-aio |
文件异步I/O使用方式与epoll基本一致,下面进行简单介绍。
初始化文件异步I/O上下文
使用如下函数初始化文件异步I/O上下文:
1 | int io_setup(unsigned nr_events, aio_context_t *ctxp) |
nr_events表示需要初始化的异步I/O上下文可以处理的事件的最小个数,ctxp是文件异步I/O上下文描述符指针。执行成功后,ctxp就是分配的上下文描述符,这个异步I/O至少可以处理nr_events个事件,返回0表示成功。
该函数与epoll_create对应。
向异步I/O上下文中增删文件操作事件
下面两个函数向异步I/O中增加、删除事件:
1 | // 增加事件,nr是一次提交事件的数量,cbp是提交事件数组的首地址。返回值表示成功提交的事件个数 |
其中使用到的iocb定义如下:
1 | struct iocb { |
其中aio_lio_opcode取值范围如下:
1 | typedef enum io_iocb_cmd { |
nginx中仅使用了IO_CMD_PREAD。
对应io_event下面介绍。
获取已完成事件
1 | int io_getevents(aio_context_t ctx, long min_nr, long nr, struct io_event *events, struct timespec *timeout); |
从已完成文件异步I/O的操作队列中读取操作。min_nr是最小返回事件数量,nr表示最大返回事件数量,events是执行完成的事件数组。timeout是超时时间,即获取到min_nr事件前的等待事件。
这里使用到了io_event结构,定义如下:
1 | struct io_event{ |
这样,根据获取到的io_event结构体数组,就可以获取已完成的异步I/O操作了。其中iocb和io_event可以传递指针,因此业务中数据结构、事件完成后的回调方法都在其中。
关闭异步I/O上下文
进程退出时,需要关闭异步I/O上下文,方法如下:
1 | int io_destroy(aio_context_t ctx); |
返回0表示成功。与epoll结束时close类似。
系统事件模块eventfd
在Linux系统中,eventfd是一个用来通知事件的文件描述符。可以使用eventfd来触发事件通知。在nginx中也会使用该方法,用于绑定消息通知和将文件异步I/O和epoll驱动。
创建eventfd
1 | int eventfd(unsigned int initval, int flags); |
创建一个eventfd对象,或者说打开一个eventfd的文件,类似普通文件的open操作。
该对象是一个内核维护的无符号的64位整型计数器。初始化为initval的值。
flags可以以下三个标志位的OR结果:
- EFD_CLOEXEC:FD_CLOEXEC,简单说就是fork子进程时不继承,对于多线程的程序设上这个值不会有错的。
- EFD_NONBLOCK:文件会被设置成O_NONBLOCK,一般要设置。
- EFD_SEMAPHORE:(2.6.30以后支持)支持semophore语义的read,简单说就值递减1。
对于eventfd就只是一个计数器,一般用于记录绑定到其上的事件触发数量。一般与epoll模块配合使用,后文会详细介绍nginx如果使用eventfd和epoll。
读eventfd
1 | int read(int efd, void *buf, size_t nbytes);// 或者int eventfd_read (int __fd, eventfd_t *__value); |
读取当前事件对应计数数值。在nginx中就是获取绑定到efd上的事件触发数量。这里如果eventfd计数不为0,并且未设置为EFD_SEMAPHORE则,计数清零,返回buf中存储计数数量,read返回读取字节数。如果eventfd计数不为0,并且设置了EFD_SEMAPHORE则,计数减一。如果eventfd为0,没有设置EFD_NONBLOCK,进程阻塞,直到计数不为0。如果eventfd为0,设置了EFD_NONBLOCK,则直接返回。
写eventfd
1 | int write(int efd, void *buf, size_t nbytes);// 或者int eventfd_write (int __fd, eventfd_t __value); |
这里的写并非直接设置eventfd值,而是对eventfd的引用计数进行增加。对于和epoll配合使用的eventfd,这一步一般不需要用户自己写入,而是在eventfd绑定的事件触发时由epoll自己写入。
关键结构
事件模块中存在一些关键结构,用于构建整个事件驱动的运行,这里进行详细介绍。
ngx_event_s事件结构
ngx_event_s定义了事件,其内容如下:
1 | typedef void (*ngx_event_handler_pt)(ngx_event_t *ev); |
ngx_connection_t连接
ngx_connection_t定义了连接,其内容如下:
1 | struct ngx_connection_s { |
其中接收发送字符流方法定义如下:
1 | typedef ssize_t (*ngx_recv_pt)(ngx_connection_t *c, u_char *buf, size_t size); |
ngx_connection_t连接池
Nginx接受客户端连接时,所使用的ngx_connection_t结构体在启动阶段就域分配好的(详见ngx_event_core_module模块的init_process方法),使用时从连接池中获取即可。
连接池结构示意图:
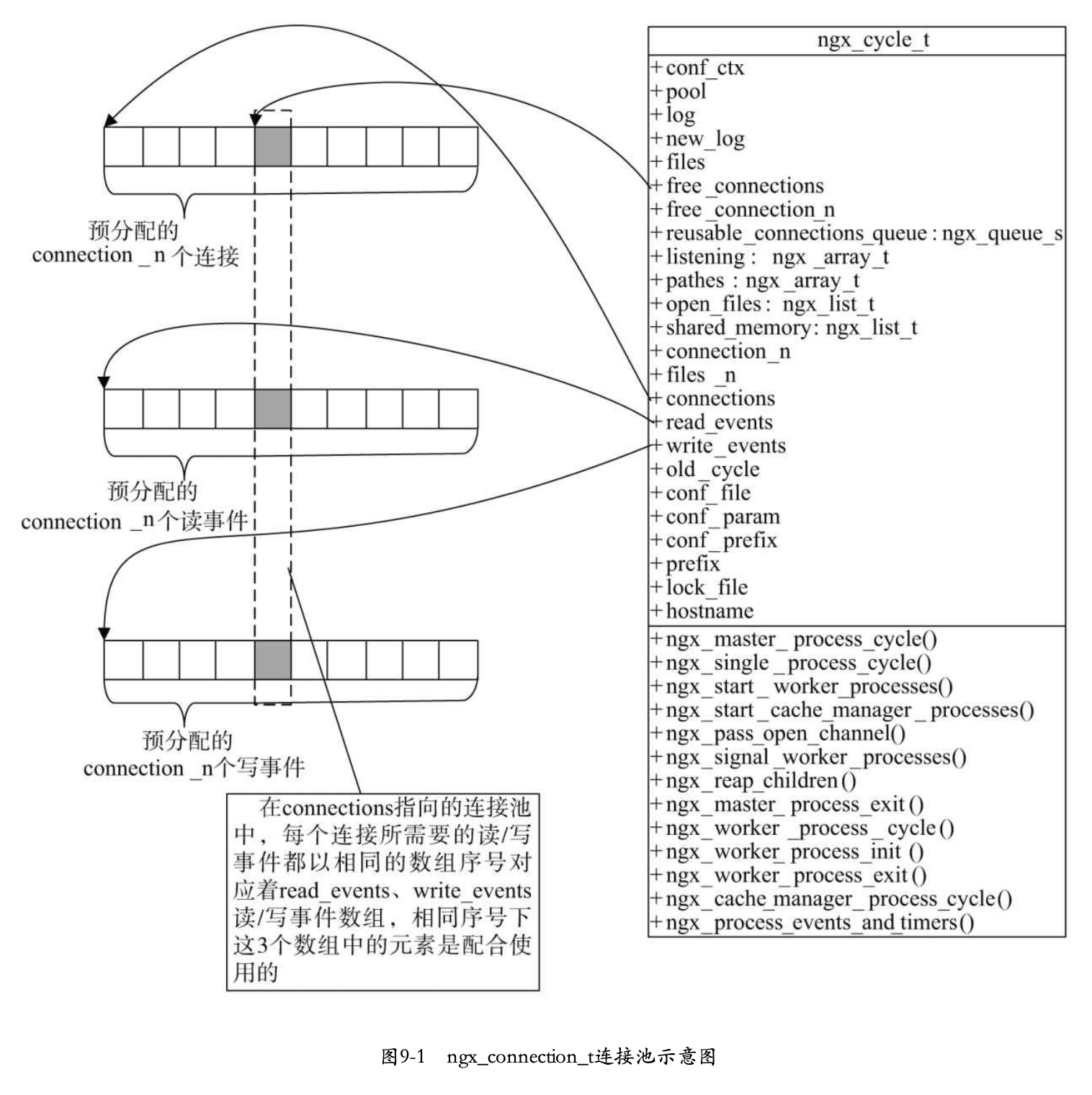
cycle中的connections和free_connections两个成员构成一个连接池,其中connections指向整个连接池数组的首部,free_connections指向第一个空闲的ngx_connection_t空闲连接。所有空闲连接通过ngx_connection_t的data成员作为next指针串联成一个单链表。当有用户发起连接时,就从free_connections指向的链表头部获取一个空闲连接,同时free_connections指向下一个空闲ngx_connection_t。归还连接时将对应的ngx_connection_t插入free_connections头部即可。
上图不止展示了连接池,同时还有事件池。Nginx认为每一个连接都至少需要一个读事件和写事件。有多少个连接就分配对应数量的读事件池和写事件池,并通过ngx_connection_t中的指针绑定对应的两个事件,ngx_event_t事件也存在指向ngx_connection_t的指针。这样将每个连接关联一个读事件和写事件。这一步也是在ngx_event_core_module模块的init_process方法进行设置的。
这里还有reusable_connections_queue可复用连接池,其是一个双向链表,其存在可以被复用的连接,当连接池剩余数量较少时,会优先释放可费用连接池中的连接,来进行建立新连接。
对于连接池,封装了如下方法。
ngx_get_connection获取空闲事件
1 | ngx_connection_t * |
ngx_free_connection释放连接
1 | void |
ngx_reusable_connection变更连接可复用性
1 | void |
这里可能有个疑问,为啥要不考虑可复用性就先执行删除操作。个人理解这与其释放顺序有关,对于先加入的可复用连接,预期会是先释放的,因此这里重新设置可执行性时,相当于重新设置了舒服的优先顺序,因此即使可复用性是否变更,都要先执行删除操作。对于先加入的先删除,较为简单,添加的时候是向链表头部添加,删除的时候从链表的最后进行遍历。
ngx_drain_connections加速释放可复用连接
1 | static void |
注意,这是静态方法,即是连接内部调用的方法。
事件处理方法
事件驱动,必然定义了很多对于事件的处理方法,这里进行详细介绍,主要包括epoll模块action中定义的一系列方法和一些主要的事件处理方法。
先来看一下epoll模块action定义的事件。
1 | static ngx_event_module_t ngx_epoll_module_ctx = { |
ngx_epoll_init初始化事件模块
首先被调用的方法就是初始化事件模块,其处理过程在ngx_event_core_module的init_process方法中,即worker子进程刚启动后。其逻辑如下:
1 | static ngx_int_t |
ngx_epoll_notify_init初始化消息提醒
1 | static ngx_int_t |
notify事件触发的处理方法
对于该事件的处理函数为:
1 | static void |
由于epoll使用的是边缘触发,因此不需要每次都执行read操作,因此这里只在必须使用的时候,才进行了read的调用。
向notify中写入事件
对应的,向notify_fd中写入事件的方法为:
ngx_epoll_module的action中的ngx_epoll_notify方法,其处理逻辑为:
1 | static ngx_int_t |
ngx_epoll_aio_init初始化文件异步I/O
1 | static void |
这里将系统的eventfd和文件异步I/O描述符和epoll三者进行关联。在epoll中监控系统eventfd(ngx_eventfd),在异步I/O中添加读取事件时,利用iocb中的aio_resfd(异步通知的fd)绑定到eventfd(ngx_eventfd)上。当异步I/O事件后,epoll_wait()将会返回eventfd(ngx_eventfd)对应的事件,并将eventfd(ngx_eventfd)计数加一,其中事件的ptr指针,指向ngx_eventfd_conn,执行ngx_eventfd_conn的read事件中的方法ngx_epoll_eventfd_handler。ngx_epoll_eventfd_handler方法将通过异步I/O描述符全局变量ngx_aio_ctx获取已完成的事件。
下面分别看一下如何条件异步I/O事件和处理异步I/O事件。
增加异步I/O事件
ngx_file_aio_read函数向ngx_aio_ctx描述符中条件异步I/O事件。
其中ngx_event_aio_t结构定义了添加异步I/O的相关结构,定义如下:
1 | struct ngx_event_aio_s { void *data; // 异步I/O事件完成后被调用的方法 ngx_event_handler_pt handler; ngx_file_t *file; ngx_fd_t fd;#if (NGX_HAVE_AIO_SENDFILE || NGX_COMPAT) ssize_t (*preload_handler)(ngx_buf_t *file);#endif#if (NGX_HAVE_EVENTFD) // 对应io_getevents返回的ngx_event_aio_t结构中的res,用于判断标志是否执行成功 int64_t res;#endif#if !(NGX_HAVE_EVENTFD) || (NGX_TEST_BUILD_EPOLL) ngx_err_t err; size_t nbytes;#endif // 添加异步I/O事件的结构 ngx_aiocb_t aiocb; // 绑定的事件,用于完成异步I/O后执行相应操作 ngx_event_t event;}; |
对于文件来说,nginx定义了ngx_file_t结构,其定义如下:
1 | typedef struct stat ngx_file_info_t; |
具体添加函数为:
1 | ssize_t |
这里初始化aio方法如下:
1 | ngx_int_t |
注意,上述的处理中对ngx_event_aio_t结构的handler未进行处理,但该值是必须要有的,因为后续会使用(下一节介绍),这里对handler的赋值可能在执行ngx_file_aio_read前,即已经完成file中aio的分配,并设置了aio的handler。或者在函数返回后,设置file中的aio成员handler。因为在所有事件传递中都是传递的指针,因此在事件添加后再进行对aio的变更并不会有问题。
epoll事件异步I/O返回的处理
在初始化aio时,设置的事件触发后的执行函数为ngx_epoll_eventfd_handler,其执行逻辑为:
1 | static void |
这里虽然我们通过读取read(ngx_eventfd, &ready, 8)获取已经准备完成的异步I/O事件数量,但实际处理的数量不一定就是ready中的值。有可能大于,有可能小于,有可能等于。
这是因为,在调用read后,循环执行的过程中,可能还有新的异步I/O事件完成,此时,在while循环中可能将新的完成事件也返回,这时,本轮就会处理比从read中读取的异步I/O完成的事件多的时间。同时这可能导致下一轮循环时,处理的事件少于从read中读取的数量,因此在上一轮已经处理了一部分了。
这里执行的事件处理函数为在添加异步I/O事件时,事件绑定的handler:
1 | static void |
因为最终会执行aiocb绑定的handler方法,因此上文说过在添加异步I/O一定要保证设置了handler方法。
ngx_epoll_test_rdhup测试epoll监听事件
ngx_epoll_test_rdhup方法用来测试是否能够监听客户端主动关闭连接。
1 | static void |
ngx_epoll_process_events事件处理
1 | // timer为调用epoll_wait等待时间,flags为按位的flags |
这里有两点需要详细进行介绍,一个是延迟处理,另一个是事件过期标志。
事件处理支持将每个触发的事件进行延后处理,其实现是一个双向链表,这里将要延后处理的事件添加到上线链表中,在执行完成ngx_epoll_process_events事件后,再依次执行添加进双向链表中的事件,执行每个的handler函数。
ngx_events_t中存在一个instance成员用来和连接的地址的最后一位比对,判断是否为过期连接。一般我们在释放连接时,会将对应的fd置为-1。这样也可以作为事件过期标志,但是这无法解决所有问题。例如如下一个场景:有三个事件触发了,第一个事件处理中·关闭了一个连接,这个连接恰好对应第三个事件,这样的化,处理第三个事件就是过期事件了。第一个事件会可能会调用ngx_free_connection将fd置为-1,并将连接归还连接池中。但第二个事件建立一个新连接,会调用ngx_get_connection(查看连接池章节)从连接池中获取一个连接,这很可能会是我们上一个事件释放的连接。这时会重新对连接的fd赋值,此时只使用fd就无法判断过期状态了。
对于上述问题解决方案是,在ngx_get_connection中获取连接池时,会将连接对应读写事件的instance置反,这时就可以通过判断事件ptr指针的最后一位(利用指针最后两位一定为0,使用最后一位作为标志位)是否与事件的instance一致来判断是否为过期事件。正常情况下事件的instance和事件返回的ptr指针最后一位一致。
将事件的instance和事件的ptr指针设置为相同发生在添加事件时,下文会详细介绍。
因此整体流程是:添加事件时,连接绑定的事件的instance和事件返回的ptr指针(指向连接)的最后一位一致,之后释放连接,当再次使用连接时,将连接对应的读写事件结构的instance取反,此时事件的instance和ptr的最后一位不一致,用于判断为过期事件,最后再将事件添加到epoll驱动时,将监控事件的结构ptr(执行连接)的最后一位和连接绑定的事件的instance统一。
不失一般性,假设从开始将事件加入epoll时,ptr指针的最后一位和事件的instance都是0(也可以都是1,但要一致)开始,则这两个变量值的随事件流转变化可以表示为如下图形式:

对于添加事件到epoll接下来详细介绍。
ngx_epoll_add_event添加事件到epoll中
该方法向epoll中添加监听事件:
1 | // event表示是读事件还是写事件,flags标注关注的事件,即epoll_event结构的events |
ngx_epoll_del_event从epoll中删除事件
1 | static ngx_int_t |
ngx_epoll_add_connection
1 | static ngx_int_t |
ngx_epoll_del_connection客户端关闭连接
1 | static ngx_int_t |
ngx_epoll_add_connection和ngx_epoll_del_connection与ngx_epoll_add_event和ngx_epoll_del_event区别是前两者是在连接纬度(包括读写两个事件)进行添加和删除事件,而后两者是在事件纬度(单独的读或者写事件纬度)进行添加或删除事件。
ngx_epoll_done结束事件处理
在关闭nginx前,会释放epoll模块创建的资源,这时会执行该操作。
1 | static void |
定时器事件
上文介绍的所有模块都是基于I/O操作的事件驱动,这样并不能解决所有问题。这样做不到每个连接内的多阶段处理,因此nginx架构自身实现了基于事件的定时器事件。
定时器的实现是利用一颗以时间作为key的红黑树。在worker进程处理循环中,查找该树中已经触发超时的节点,执行对应的处理函数。因此时间控制就显得尤为重要。
缓存时间管理
缓存时间在进程间是不共用的,也就是说,病危使用mmap内存映射将多个进程读写同一个地址的数据。每个worker要维护自己的时间缓存。
处于性能考虑,一般不会在每次需要使用时间时调用gettimeofday来更新时间,而是将时间缓存到一些全局变量中,在必要的时候再进行更新。
nginx缓存了如下关于时间的全局变量:
1 | typedef struct { |
对于nginx自己定义的定时器事件来说,对于时间是十分敏感的,因此何时更新缓存的时间是是否重要的。
nginx更新缓存事件分为两种情况:
- 配置了timer_resolution:如果配置中存在该配置,则会在每次worker进程的循环中,判断定时器是否已经触发,触发时进行时间更新。其中worker进程增加时钟信号在ngx_event_core_module模块的int_process方法中(详情可查看上文介绍),事件循环中,对应epoll_wait等待事件为-1,即直到等待有事件触发或者时钟信号触发时,就会更新时间。
- 当没有配置timer_resolution时,则每次worker进程循环的时候,都会执行事件更新。这时epoll_wait等待事件则取决于定时器事件中当前是否存在超时事件,如果存在,则时间为0,即不等待,直接返回,如果没有,则最多等待最近的一个事件所对应的事件。具体查看ngx_process_events_and_timers函数。
ngx_time_init初始化时间
1 | void |
ngx_time_update更新时间
1 | void |
这里比较有趣的就是slot的使用。对于写操作,是使用锁进行更新,保证数据不会被损坏,对于读操作,是并未加锁的,直接从缓存中读取的。如果在读取的时候,有别的线程在写入,将会导致读取出的数据是被损坏的,这里使用一个数组来进行写进行规避。
1 | #define NGX_TIME_SLOTS 64 |
从上面的定义可以看出来,除了ngx_current_msec全局变量,其余每一个变量都有一个与之对应的64纬数组。slot变量记录了当前缓存中的全局变量的值是那个数组中存储的数据,每次更新的时候,都将slot增加1,这样保证更新的是缓存中的后一个数据,在更新完成后,统一将内容写入到全局变量中,以此来保证读操作时,不会有写线程来导致全局变量是被损坏的数据。
比如,在线程A在复制ngx_cached_http_time的data字段时(赋值了一半),这时被信号中断,或者别的线程重写了数据,如果没有slot,则复制过程中,后面地址的内容将会是错误数据,有了slot后,一般情况变更不会将原来地址的数据重写(除非一下有64个线程调用了时间更新),这样在一定程度上保证了读操作的安全性(不能完全避免)。目前未使用多线程,目前可以不用考虑。
定时器方法
ngx_event_timer_init初始化定时器红黑树
1 | ngx_rbtree_t ngx_event_timer_rbtree; |
事件时间红黑树中会存在key一致的问题,但并未做任何处理,因为对其中的元素来说,我们并不会要精确获取哪一个,只是在时间触发时,执行对应元素的处理即可。
初始化红黑树详见红黑树的介绍。
ngx_event_add_timer向事件树中增加元素
1 | static ngx_inline void |
ngx_event_del_timer从事件树中删除元素
1 | static ngx_inline void |
ngx_event_find_timer查找是否存在超时事件
1 | ngx_msec_t |
ngx_event_expire_timers执行所有的超时事件
1 | void |
因此事件一旦超时,将会执行处理函数,并从事件红黑树中删除。在nginx中,对于某些事件会同时添加到事件红黑树和epoll事件驱动模块中,例如,在建立连接后,接收请求有一个超时时间。因此向事件红黑树和epoll中均添加上对应等待请求的事件。如果在指定时间内还未收到请求,则事件红黑树中将执行超时处理,设置事件为超时事件,并执行相应的处理(关闭连接,从epoll中剔除事件)。如果在超时之前接收到了请求,则会先执行对应的处理,如果在指定时间内未完成获取请求头和解析,导致定时器红黑树中事件触发,依然会将事件移出,并关闭连接,如果在指定事件完成上述操作,则会将事件从定时器红黑树中移出。
ngx_event_no_timers_left检查是否所有事件均可忽略
在worker进程退出时,会判断是否所有事件均可以忽略,如果是,则直接退出。
1 | ngx_int_t |
一些重要的模块
pcre正则
在nginx中使用pcre正则来解析配置并进行处理。PCRE是 ‘Perl Compatible Regular Expressions’(Perl兼容的正则表达式)的缩写。PCRE库由一系列函数组成,实现了与Perl5相同的语法、语义的正则表达式匹配功能。
正则需要进行模式匹配,其中包含命名模式匹配和匿名模式匹配,以如下为例:
1 | (?<date> (?<year>(\d\d)?\d\d) - (?<month>\d\d) - (?<day>\d\d) ) |
这里存在5个匹配(包括匿名匹配和命名匹配)。其中date匹配(?<year>(\d\d)?\d\d) - (?<month>\d\d) - (?<day>\d\d)部分,year匹配(\d\d)?\d\d,month匹配\d\d,day匹配\d\d。还包含一个匿名匹配,即year后面的(/d/d)。
PCRE允许使用命名捕获分组,也允许使用匿名捕获分组(即分组用数字来表示),其实命名捕获分组只是用来标识分组的另一种方式,命名捕获分组也会获得一个数字分组名称。PCRE提供了一些方法可以通过命名捕获分组的名称来快速获取捕获分组内容的函数,比如:pcre_get_named_substring() .
也可以通过以下步骤来获取捕获分组的信息:
将命名捕获分组的名称转换为数字。
通过上一步的数字来获取分组的信息。
这里就牵涉到了一个name to number的转换过程,PCRE维护了一个name-to-number的map,我们可以根据这个map完成转换功能,这个map有以下三个属性:1
2
3PCRE_INFO_NAMECOUNT
PCRE_INFO_NAMEENTRYSIZE
PCRE_INFO_NAMETABLE这个
map包含了若干个固定大小的记录,可以通过PCRE_INFO_NAMECOUNT参数来获取这个map的记录数量(其实就是命名捕获分组的数量),通过PCRE_INFO_NAMEENTRYSIZE来获取每个记录的大小,这两种情况下,最后一个参数都是一个int类型的指针。其中每个每个记录的大小是由最长的捕获分组的名称来确立的。其中每个每个记录的大小是由最长的捕获分组的名称来确立的。这里的记录是说命名的大小。PCRE_INFO_NAMETABLE返回一个指向这个map的第一条记录的指针(一个char类型的指针),每条记录的前两个字节是命名捕获分组所对应的数字分组值,剩下的内容是命名捕获分组的name,以'\0'结束。返回的map的顺序是命名捕获分组的字母顺序。对于上述
date的例子来说,map中存储数据内容如下:1
2
3
400 01 d a t e 00 ??
00 05 d a y 00 ?? ??
00 04 m o n t h 00
00 02 y e a r 00 ??其中
PCRE_INFO_NAMEENTRYSIZE为8,因为最长的name是moth,加上前面两位表示对应的实际数字分组值,已经最后的\0,总共八位。对应长度小于8位的命名分组来说,超长的部分是未设置值的。在遍历map时,需要使用PCRE_INFO_NAMEENTRYSIZE作为偏移。
这里主要介绍一下nginx中使用的pcre方法。
pcre_compile()
函数原型:
1 | pcre *pcre_compile(const char *pattern, int options, const char **errptr, int *erroffset, const unsigned char *tableptr) |
功能: 将一个正则表达式编译成一个内部的pcre结构,在匹配多个字符串时,可以加速匹配。其中pcre_compile2()功能一样,只是缺少一个参数errorcodeptr。
pattern为字符串,表示待编译的正则表达式。
options为0或者其他可选的标志。
errptr为返回的出错信息。
erroffset为出错位置。
tableptr指向一个字符数组的指针,可以设置为NULL。
pcre_study()函数
函数原型:
1 | pcre_extra *pcre_study(const pcre *code, int options, const char **errptr) |
功能: 对编译的模式进行学习,提取可以加速匹配过程的信息。
code为已编译的模式,即pcre_compile函数的输出。
options为选项。目前只有一个options,即PCRE_STUDY_JIT_COMPILE表示如果可能,它会要求及时编译。
errpetr为出错信息。
pcre_exec()函数
函数原型:
1 | int pcre_exec(const pcre *code, const pcre_extra *extra, const char *subject, int length, int startoffset, int options, int *ovector, int ovecsize) |
功能: 使用编译好的模式进行匹配,采用与Perl相似的算法。返回值大于0,表示匹配到的pattern个数; 否则表示出错信息。NGX_REGEX_NO_MATCHED表示不匹配(-1),其他负数表示错误。
code为编译好的模式。
extra为pcre_extra结构体,可以为null。
subject为需要匹配的字符串。
length为匹配字符串长度。
startoffset为匹配的开始位置。
options为选项位。
ovector指向一个结果的整形数组。这里返回的是每个捕获相对于subject中的偏移,对于第$i$个捕获来说,其起始下标为$ovector[2i]$,末尾下标为$ovector[2i+1]$。其中$i$从0开始。
ovecsize数组大小。
pcre_fullinfo函数
函数原型:
1 | int pcre_fullinfo(const pcre *code, const pcre_extra *extra,int what, void *where); |
功能:返回一个被编译完成的pattern的相关信息。
code为编译完成的pattern。
extra为优化后的额外信息,可以为空。
what为需要获取的信息类型。
where返回对应的存放地址。
nginx中主要获取到如下信息:
| what | 含义 |
|---|---|
PCRE_INFO_CAPTURECOUNT |
捕获子模式的数量 |
PCRE_INFO_NAMECOUNT |
命名子模式的数量 |
PCRE_INFO_NAMEENTRYSIZE |
名称表条目的大小 |
PCRE_INFO_NAMETABLE |
指向名称表的指针 |
PCRE_INFO_JIT |
是否支持JIT |
pcre_config函数
函数原型:
1 | int pcre_config(int what, void *where) |
功能: 查询当前PCRE版本中使用的选项信息。
- what: 选项名
- where: 存储结果的位置
nginx中使用pcre
nginx中使用正则主要通过ngx_regex_module模块处理,这里不详细介绍该模块的所有部分,只关注对正则的处理。
相关结构
1 | typedef struct { |
ngx_regex_compile编译正则
ngx_regex_compile函数用来对正则进行编译并初始化对应的ngx_regex_compile_t结构:
1 | ngx_int_t |
ngx_regex_exec执行匹配
1 | #define ngx_regex_exec(re, s, captures, size) \ |
由于nginx中不需要额外指定其余参数,因此设置了一个宏定义来减少参数,执行匹配。
ngx_regex_exec_array匹配正则数组
ngx_regex_exec_array函数查找一个字符串是否匹配一个正则数组中的任意一个:
1 | // a为ngx_regex_elt_t的数组 |
rewrite模块
配置解析
1 | static ngx_command_t ngx_http_rewrite_commands[] = { |
相关结构
ngx_http_rewrite_loc_conf_t
该结构为rewrite模块生成的loc下的配置数据,其定义如下:
1 | typedef struct { |
codes数组设置比较独特。脚本指令都是实现了”接口ngx_http_script_code_pt”的各个不同的充当类的结构体,这些结构体可以是ngx_http_script_var_code_t、ngx_http_script_value_code_t等,其类型不同,占用的内存也不同,如何放入一个数组中呢(不是它们的指针)。通过如下三点做到:
codes数组设计每个元素仅占用1字节大小,即不奢望一个数组元素能够存放表示一个脚本指令的结构体。
每次要将1个指令放入codes数组中时,将根据指令结构体的占用内存字节数N,在codes数组中分配N个元素存储这1个指令,再依次把指令结构体的内容都拷贝到这N个数组成员中。例如:
1
2
3
4
5
6
7
8
9
10
11
12void *
ngx_http_script_start_code(ngx_pool_t *pool, ngx_array_t **codes, size_t size)
{
if (*codes == NULL) {
*codes = ngx_array_create(pool, 256, 1);
if (*codes == NULL) {
return NULL;
}
}
return ngx_array_push_n(*codes, size);
}HTTP请求到来,脚本指令执行时,每执行完一个脚本指令的ngx_http_script_code_pt方法后,该方法必须主动告知所属指令结构体占用的内存数N,这样从当前指令所在codes数组索引加上N后就是下一条指令。
ngx_regex_compile_t
ngx_regex_compile_t结构用于正则表达式的编译,定义如下:
1 | typedef struct { |
ngx_http_regex_t
ngx_http_regex_t结构存储http模块使用正则的相关内容:
1 | typedef struct { |
ngx_http_regex_variable_t
对于正则表达式中使用的命名匹配来说,nginx会将其增加到变量数组中,ngx_http_regex_variable_t结构存储了相关结构:
1 | typedef struct { |
ngx_http_script_engine_t
同一段脚本被编译进nginx中,在不同请求中执行效果是不一样的,所以每个请求都必须有其独特的脚本执行上下文,或者称为脚本引擎。这由ngx_http_script_engine_t类充当:
1 | typedef struct { |
sp是一个栈,作为编译工具。大小默认为10.
ip可以理解为IP寄存器,指向下一行将要执行的代码。对于u_char*类型来说,其指向类型是不定的。其指向的一定是待执行的脚本指令。用面向对象的语言来说,其指向的是实现了ngx_http_script_code_pt接口的类。但C语言没有接口的概念,在C语言实现上述目的,通常会使用嵌套结构体的方法,比如表示接口的结构体A,要放在表示实现接口的类-结构体B的第一个位置。这样一个指向B的指针,也可以强制转换为A,再调用A的成员。ngx_http_script_code_pt是一个指针函数:
1 | typedef void (*ngx_http_script_code_pt) (ngx_http_script_engine_t *e); |
ngx_http_script_code_pt参数ngx_http_script_engine_t,其表示当前指令的脚本上下文。
ngx_http_script_compile_t
ngx_http_script_compile_t结构用于执行脚本的解析编译。
1 | typedef struct { |
ngx_http_script_regex_code_t
ngx_http_script_regex_code_t用于存储rewrite中第一个正则表达式的相关信息及对应的处理方法。
1 | typedef struct { |
ngx_http_script_regex_end_code_t
ngx_http_script_regex_end_code_t用于存储生成rewrite中第二个新的uri时需要的参数及方法
1 | typedef struct { |
create location方法
1 | static void * |
commands方法
rewrite配置
语法:rewrite regex replacement [flag];
作用域:server 、location、if
功能:如果一个URI匹配指定的正则表达式regex,URI就按照 replacement 重写。
rewrite 按配置文件中出现的顺序执行。可以使用 flag 标志来终止指令的进一步处理。
如果 replacement 以 http:// 、 https:// 或 $ scheme 开始,将不再继续处理,这个重定向将返回给客户端。
flag 有四种参数可以选择:
last停止处理后续 rewrite 指令集,然后对当前重写的新 URI 在 rewrite 指令集上重新查找。break停止处理后续 rewrite 指令集,并不再重新查找。一般break和代理转发进行配合使用,注意,如果没有break,则新生成的uri会重新执行NGX_HTTP_FIND_CONFIG_PHASE阶段,而使用了break,则不会再进行查找,例如:1
2
3
4
5location ~ ^/test/(.*)$ {
rewrite /test/(.*) /test/index.php/$1 break;
proxy_pass http://backend;
}这时会按照新生成的uri进行代理转发。
redirect如果replacement不是以http://或https://开始,返回302临时重定向。permanent返回301永久重定向。
rewrite对uri进行改写。
1 | { ngx_string("rewrite"), |
其对应方法函数如下:
1 | static char * |
ngx_http_regex_compile
该方法对正则表达试进行编译。
1 | ngx_http_regex_t * |
ngx_http_script_regex_start_code
该函数添加到了ngx_http_rewrite_loc_conf_t中的codes类的实际执行方法。该方法进行正则匹配,并进行相关设置。
1 | void |
ngx_http_regex_exec
执行http正则匹配:
1 | ngx_int_t |
ngx_http_script_compile
该函数负责对新生成的uri的构建工作,对表达式进行解析,并在codes中增加响应的处理函数。
1 | ngx_int_t |
ngx_http_script_add_capture_code
添加匿名捕获处理函数:
1 | // 其中n为匿名捕获对应的数值 |
其中ngx_http_script_copy_capture_code_t定义如下:
1 | typedef struct { |
其中长度处理函数逻辑为:
1 | size_t |
对应的值处理逻辑为:
1 | void |
ngx_http_script_add_var_code
该方法增加命名捕获变量的处理:
1 | static ngx_int_t |
其中ngx_http_script_var_code_t定义如下:
1 | typedef struct { |
其中计算长度函数为:
1 | size_t |
获取值函数为:
1 | oid |
ngx_http_script_add_copy_code
该函数增加简单的值拷贝处理逻辑。
1 | // last判断是否为值的末尾 |
其中ngx_http_script_copy_code_t定义如下:
1 | typedef struct { |
计算长度和获取值处理如下:
1 | size_t |
ngx_http_script_add_args_code
ngx_http_script_add_args_code函数添加对参数的处理。
1 | static ngx_int_t |
计算长度和值的函数如下:
1 | size_t |
ngx_http_script_add_code
该函数向codes数组中添加元素,但多了一个参数。
1 | void * |
该处理函数的code含义为,对于添加元素来说,当先前分配的地址不够直接添加时,会生成一个新的更大的地址,这时旧的code地址就无法继续使用了,但执行完该函数后,好需要继续使用code,这时就需要计算新的code所在地址,找到新的地址,继续使用。
ngx_http_script_regex_end_code
ngx_http_script_regex_end_code函数对完成rewrite方法后进行处理。
1 | void |
if 配置
merge location方法
ngx_http_rewrite_merge_loc_conf为mergelocation方法。其执行逻辑为:
1 | static char * |
postconfiguration方法
1 | static ngx_int_t |
向NGX_HTTP_SERVER_REWRITE_PHASE和NGX_HTTP_REWRITE_PHASE阶段增加处理函数。
ngx_http_limit_req_module
该模块主要用于限流,在NGX_HTTP_PREACCESS_PHASE阶段执行。
1 | static ngx_command_t ngx_http_limit_req_commands[] = { |
相关结构
ngx_http_limit_req_conf_t
该结构为模块创建的location的配置。
1 | typedef struct { |
ngx_http_limit_req_ctx_t
该结构为限制的详细信息:
1 | typedef struct { |
ngx_http_limit_req_shctx_t
对于限制来说,我们炫耀快速超找到某个限制是否对当前请求是否存在。使用红黑树存储信息来加速查找。
1 | typedef struct { |
ngx_http_complex_value_t
对于限制的纬度来说,允许用户任意进行设置,因此可能是一个复杂的变量值,因此需要一个结构承接对请求中该纬度的计算。结构如下:
1 | typedef struct { |
ngx_http_limit_req_node_t
该结构存储限制信息:
1 | typedef struct { |
create location
create location函数为ngx_http_limit_req_create_conf,其执行逻辑为:
1 | static void * |
limit_req_zone配置
语法及含义
配置语法为:
1 | limit_req_zone key zone=name:size rate=rate [sync]; |
该配置设置一个监控纬度,其中key可以是文本,变量或者联合值,name表示监控的名字,用于在limit_req中使用。size为允许为该监控创建的共享内存大小,rate为每一个key,请求的出现的频率。例如:
1 | limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s; |
这里的key是请求的二进制地址,这里使用二进制地址而不是remote_addr是为了节省空间考虑的,对于ipv4来说,二进制地址占用4byte空间,对于ipv6来说,二进制地址占用16bytes空间。1M大概能够存储16000个地址信息(这里不止有地址,还包括其状态信息)。
如果区域存储耗尽,则删除最近最少使用的状态。 如果即使在此之后无法创建新状态,请求也会因错误而终止。
速率以每秒请求数 (r/s) 为单位指定。 如果需要每秒小于一个请求的速率,则以每分钟请求数 (r/m) 指定。 例如,每秒半请求为 30r/m。
sync 参数启用共享内存区域的同步。
解析配置方法
1 | static char * |
共享内存初始化
在执行该值前,会已经为shm_zone->shm.addr分配了对应size的内存映射(mmap),,可查看ngx_init_cycle函数(其中的ngx_shm_alloc,会按照shm的size分配大小)。
1 | static ngx_int_t |
limit_req配置
语法及含义
语法为:
1 | limit_req zone=name [burst=number] [nodelay | delay=number]; |
设置共享内存区域和请求的最大突发大小。 如果请求速率超过为区域配置的速率,则它们的处理将被延迟,以便以定义的速率处理请求。 过多的请求会被延迟,直到它们的数量超过最大突发大小,在这种情况下,请求会因错误而终止。 默认情况下,最大突发大小为零。 例如,指令:
1 | limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s; |
平均每秒允许不超过 1 个请求,突发不超过 5 个请求。超过5个的请求会直接丢弃。
如果不希望在请求受到限制时延迟过多的请求,则应使用参数 nodelay:
1 | limit_req zone=one burst=5 nodelay; |
delay 参数指定过多请求延迟的限制。 默认值为零,即所有过多的请求都被延迟。只有在设置了burst时才有意义,delay表示超过设置的速率,但没有超过burst的请求中,前k个会被立即处理,超过delay的数量才会被延迟处理。
可能有几个 limit_req 指令。 例如,以下配置将限制来自单个 IP 地址的请求的处理速率,同时限制虚拟服务器的请求处理速率:
1 | limit_req_zone $binary_remote_addr zone=perip:10m rate=1r/s; |
配置解析方法
1 | static char * |
其他配置
剩下的配置较为简单,这里进行简单介绍.
limit_req_log_level该配置设置在由于超过burst限制时拒绝服务的log等级。
1 | Syntax: limit_req_log_level info | notice | warn | error; |
limit_req_status设置拒绝服务时返回的状态码。
1 | Syntax: limit_req_status code; |
limit_req_dry_run启用试运行模式。 在这种模式下,请求处理速率不受限制,但是在共享内存区域中,过度请求的数量照常计算。
1 | Syntax: limit_req_dry_run on | off; |
merge location方法
merge方法较为简单:
1 | static char * |
preconfiguration方法
该方法添加一个变量。
1 | static ngx_http_variable_t ngx_http_limit_req_vars[] = { |
postconfiguration方法
该方法向NGX_HTTP_PREACCESS_PHASE阶段增加一个处理函数:
1 | static ngx_int_t |
处理函数ngx_http_limit_req_handler
1 | static ngx_int_t |
ngx_http_complex_value计算请求在该zone的key
1 | ngx_int_t |
ngx_http_limit_req_unlock删除当前请求在前n个zone中的记录
1 | static void |
ngx_http_limit_req_lookup查找节点
该函数赋值查找节点,如果不存在,则新建节点。
1 | /* |
这里需要专门介绍一个超过限制的计算,即代理的:
1 | excess = lr->excess - ctx->rate * ms / 1000 + 1000; |
首先计算是累加的,即计算时使用节点之前的lr->excess进行累加,由于超额请求可能是负数,当是负数时,设置的excess为0。
后面的先看ctx->rate * ms/ 1000,其中ctx->rate为1000允许速率(即 k r/s,每秒k个请求),ms/1000为距离上次请求的秒数,因此`ctx->rate ms / 1000为对应上次请求与该次请求的这段时间,允许的最大请求数量(再乘以1000),而这段时间的实际到底的请求数量为1个请求(这里为了和前面的1000平衡,因此后面也是1000),因此超过允许请求速率的请求数量为1000- ctx->rate * ms / 1000`。这样便计算出了超过请求速率的请求数量(乘以1000)。
ngx_http_limit_req_expire释放空闲空间
该函数对长时间无请求的节点空间进行释放:
1 | /* |
ngx_http_limit_req_account获取最大延迟处理时间
该函数遍历所有限制zone,判断是否需要对请求进行延迟处理,并获取延迟时间:
1 | /* |
这里着重介绍一下请求延迟时间的计算:
1 | delay = (excess - limits[n].delay) * 1000 / ctx->rate; |
其中excess为请求超过rate的数量,excess - limits[n].delay是请求超过delay限制的数量,可类比为距离,ctx->rate为请求限制速度,相除即得延迟时间,这里乘以1000,是因为ngix时间维度以毫秒为单位。
ngx_http_test_reading延迟处理期间读事件处理
1 | void |
ngx_http_limit_req_delay请求延时期间写事件处理
1 | static void |
这里需要参考ngx_http_request_handler处理函数,即写事件触发的处理函数。在写事件被触发时,仅有delayed是1,并且timeout为1时才会将delayed置为0。因此写事件同时被加入的事件红黑树中了,这时,在红黑树超时之前,epoll触发的写事件都不会设置请求为继续向下执行,在红黑树中的事件超时时,写事件的delayed将被设置为0,这时请求将会被向下继续执行,以此来达到限制请求处理的速率。
至此完成了ngx_http_limit_req_module模块的详细介绍。
ngx_http_limit_conn_module模块
除了上述的模块限速以外,还有ngx_http_limit_conn_module限速模块,这里不详细对该模块的原理进行介绍。注意讲一下相关配置和大概的实现原理。ngx_http_limit_conn_module 模块用于限制每个定义的键的连接数,特别是来自单个 IP 地址的连接数。
配置
limit_conn_zone配置
该配置与limit_req_zone配置类似。
1 | Syntax: limit_conn_zone key zone=name:size; |
设置限制纬度,和为限制分配的共享内存大小。
limit_conn
限制纬度下,最大允许的连接数量:
1 | Syntax: limit_conn zone number; |
实现原理
与ngx_http_limit_req_module模块类似,使用共享内存加锁来实现计数,不过区别是,一个请求会将记录的数组增加1,并注册一个cleanup函数,在结束请求时将计数减1,当减到0时就会清除该记录。
变量
在读取配置项的时候,会对变量进行初始化,包括nginx提供的内置变量和用户配置文件中的变量。
相关结构
1 | // 参数分别为请求r,表示变量值的v,以及一个可能使用到的参数data。 |
其中ngx_http_variable_s中的flag相关取值是如下值的1按位与:
| 值 | 含义 |
|---|---|
NGX_HTTP_VAR_CHANGEABLE 1 |
表示变量值可变,即对同一个请求来说,变量可以被反复修改其值。因此以上定义同一变量名与修改变量等价。 |
NGX_HTTP_VAR_NOCACHEABLE 2 |
不能缓存改变量的值,每次使用变量时都需要重新解析。有些请求的变量会在执行中随着url跳转等动作反复改变。如$uri,如果取上次缓存值,是无法知道是否正确的。 |
NGX_HTTP_VAR_NOHASH 8 |
不要将该变量hash到散列表。散列表需要消耗空间,如果某个模块设计了一个可选变量提供给其他模块使用,并且要求有其他模块使用该变量时必须索引化再使用(即不能调用ngx_http_get_variable方法获取),这样,这个变量就不用浪费散列表的空间了。 |
NGX_HTTP_VAR_WEAK 16 |
弱变量,对于set设置的变量都是弱变量,如果该变量是前缀变量,则会使用前缀变量的get_handler解析方法。 |
NGX_HTTP_VAR_PREFIX 32 |
前缀变量,如args_、cookie_、http_等,一般是nginx内置的一系列变量。 |
存储变量名的数据结构
变量被存储在main级别下的ngx_http_core_main_conf_t中:
1 | typedef struct { |
对于一个变量,可能存在于多个结构中,即variables_hash或variables或prefix_variables中。这时一个变量可能存在多份ngx_http_variable_t结构,但是需要保证,每个的都要要相等的。保证相等的操作在ngx_http_variables_init_vars方法中完成。具体见下文。
解析变量
解析变量使用get_handler方法,其原型如下:
1 | typedef ngx_int_t (*ngx_http_get_variable_pt) (ngx_http_request_t *r, |
其中r和data是用来帮助生成变量值,而v是存放值的载体。结构体v已经分配好内存(调用get_handler的函数负责),分配好的内存不包括字符串变量值。可以使用请求r的内存池来分配新的内存放置变量值,这样请求结束,内存就被释放。参数v的data和len成员指向变量值字符串即完成解析。对于data参数来说,存在多种场景。
data参数不起作用
如果只是生成一些和用户请求无关的变量值,例如时间、系统负载,那么使用各种方法获得变量后赋值给参数v的data和len即可。或者ngx_http_request_t *r中成员已经足够解析出变量值了,data参数不用也可以。
例如,HTTP架构提供的一个变量body_bytes_sent,表示一个请求的响应包体长度,常用在日志中,其解析方法如下:
1 | static ngx_http_variable_t ngx_http_core_variables[] = { |
data参数作为指针
uintptr_t是一个可以放置指针的整型,所以,uintptr_t被设计为即可以用来做整型偏移,也可以做指针。
对于5类前缀字符串,如http_、args_等,实际每个这样的变量其解析方式都大同小异,遍历解析出来的r->headers_in.headers或者r->headers_in.headers数组,找到变量名再返回其值。为了设计更加通用,就使用data作为指针指向实际的变量名字符串。如下,当出现如http_这样的变量被模块使用时,就把data作为指针来保存实际的变量名字符串v[i].name(ngx_http_variables_init_vars初始化特殊变量时的代码段)。
1 | if (ngx_strncmp(src[i].key.data, "HTTP_", sizeof("HTTP_") - 1) == 0) |
解析变量的方法get_hander将data转换为ngx_str_t*
1 | static ngx_int_t |
ngx_http_variable_unknown_header遍历ngx_list_t链表类型的headers数组,找到符合变量名的头部后,将其值作为变量返回。
data作为内存的相对偏移量
很多时候,变量值很可能是原始HTTP字符流中的一部分连续字符串,如果能够复用,就不用再为变量分配,拷贝内存了。而且HTTP模块在使用get_handler时,HTTP框架可能在请求的自动解析过程中已经得到了需要的变量值。这就是data参数作为整数设计的目的。例如:
1 | { ngx_string("http_host"), NULL, ngx_http_variable_header, |
http_host变量对应于ngx_http_request_t结构体里的headers_in成员的host成员,http_user_agent变量对应ngx_http_request_t结构体里的headers_in成员的user_agent成员。对应的处理函数为ngx_http_variable_header:
1 | static ngx_int_t |
查找变量
ngx_http_get_variable_index
设置变量被索引,并获得索引号,这是使用ngx_http_get_indexed_variable、ngx_http_get_flushed_variable方法的前置条件。调用它意味着这个变量会被频繁的使用,希望Nginx处理这个变量时效率更加高,体现在:
- 变量值可以被缓存,重复读取时不用每次都解析。
- 定义变量的解析方法时,可以通过索引直接查找到该方法进行解析,而不是通过操作散列表。
- nginx在初始化http请求时,就需要为这个变量预分配好ngx_http_variable_value_t变量结构体。
函数执行逻辑如下:
1 | ngx_int_t |
ngx_http_get_indexed_variable
根据ngx_http_get_variable_index得到的索引号,获取被索引过的变量的值。若变量被解析过一次后,其值会被缓存,这样该方法再次调用会直接获取缓存过的值,而不是重新解析。该方法忽略NGX_HTTP_VAR_NOCACHEABLE标识。
其方法如下:
1 | ngx_http_variable_value_t * |
ngx_http_get_flushed_variable
该方法与ngx_http_get_indexed_variable类似,不过其不忽略NGX_HTTP_VAR_NOCACHEABLE标识。
1 | ngx_http_variable_value_t * |
ngx_http_get_value
根据变量名称,从hash过的散列表中找到对应的变量,并调用其解析方法,获得值,这里不存在缓存变量值的可能。同时前缀变量也可以从该方法中获取解析值。
1 | ngx_http_variable_value_t * |
添加系统变量
内部变量会在系统初始化是定义。赋值是在需要使用该变量时才赋值,而不是请求到达后就优先赋值。查找变量的方式为根据索引找到系统中相应的变量或者通过hash表来进行查找。
系统变量定义都是在执行模块的proconfiguration阶段。该方法添加变量到main级别创建的ngx_http_core_main_conf_t的variables_keys(散列表)或prefix_variables(数组)中。例如,对于核心模块ngx_http_core_module对应的方法ngx_http_core_preconfiguration:
1 | static ngx_int_t |
ngx_http_add_variable
其中ngx_http_add_variable函数如下:
1 | ngx_http_variable_t * |
其中ngx_http_add_prefix_variable如下:
1 | static ngx_http_variable_t * |
从上可以看出,只有前缀并且设置可以变更的变量,可以重复添加。
外部变量和脚本引擎
出了上文提到的使用模块的preconfiguration方法来添加变量以外,还可以使用ngx_http_rewrite_moduel模块提供的set配置。其使用了Nginx的脚本引擎。
变量名称在nginx.conf的配置文件里声明,且在配置文件中确定了变量的赋值。模块定义外部变量的格式为:
1 | set $variable value |
配置通过set关键字定义了一个在nginx.conf中指定的新变量variable,并将其赋值为value。value可以是一个文本字符串,还可以包含多个变量,也可以是变量与文本字符串的组合。
相关数据结构
同一段脚本被编译进nginx中,在不同请求中执行效果是不一样的,所以每个请求都必须有其独特的脚本执行上下文,或者称为脚本引擎。这由ngx_http_script_engine_t类充当:
1 | typedef struct { |
sp是一个栈,作为编译工具。大小默认为10.
ip可以理解为IP寄存器,指向下一行将要执行的代码。对于u_char*类型来说,其指向类型是不定的。其指向的一定是待执行的脚本指令。用面向对象的语言来说,其指向的是实现了ngx_http_script_code_pt接口的类。但C语言没有接口的概念,在C语言实现上述目的,通常会使用嵌套结构体的方法,比如表示接口的结构体A,要放在表示实现接口的类-结构体B的第一个位置。这样一个指向B的指针,也可以强制转换为A,再调用A的成员。ngx_http_script_code_pt是一个指针函数:
1 | typedef void (*ngx_http_script_code_pt) (ngx_http_script_engine_t *e); |
ngx_http_script_code_pt参数ngx_http_script_engine_t,其表示当前指令的脚本上下文。
ngx_http_script_code_pt相当于抽象基类的一个接口,会有相应的结构体担当类的角色。对于”set”配置来说,编译变量名(即第一个参数)由一个实现了ngx_http_script_code_pt接口的类担当,这个类为ngx_http_script_var_code_t:
1 | typedef struct { |
第一个成员是ngx_http_script_code_pt,因此可以把ngx_http_script_var_code_t强制转换为ngx_http_script_code_pt执行。
set的第2个参数是变量值,其也需要一个结构体ngx_http_script_value_code_t来编译,其定义如下:
1 | typedef struct { |
为何一行set脚本分别由编译变量名、编译变量值的2个结构来表示呢。因为对于set有很多不同的使用场景,对变量名来说,就存在变量名首次出现与非首次出现,而变量值有纯文字、字符串与其他变量组合等情况。把变量名的编译提取为ngx_http_script_var_code_t结构体,使所以变量名的编译可以复用其index成员,而具体的ngx_http_script_code_pt指令则可以各组实现。把变量值的编译提取为ngx_http_script_value_code_t结构体,则可以复用text_len、text_data成员。
ngx_http_script_engine_t随着HTTP请求到来才创建,所以其无法保存Nginx启动时就编译出的脚本。保存编译后的脚本工作由ngx_http_rewrite_loc_conf_t结构承担。其是ngx_http_rewrite_module_ctx模块在location级别的配置结构体。其定义如下:
1 | typedef struct { |
如果location下没有脚本式配置,那么其成员codes数组就是空的,否则codes数组会放置承载者被解析后的脚本指令的结构体。
codes数组设置比较独特。脚本指令都是实现了”接口ngx_http_script_code_pt”的各个不同的充当类的结构体,这些结构体可以是ngx_http_script_var_code_t、ngx_http_script_value_code_t等,其类型不同,占用的内存也不同,如何放入一个数组中呢(不是它们的指针)。通过如下三点做到:
codes数组设计每个元素仅占用1字节大小,即不奢望一个数组元素能够存放表示一个脚本指令的结构体。
每次要将1个指令放入codes数组中时,将根据指令结构体的占用内存字节数N,在codes数组中分配N个元素存储这1个指令,再依次把指令结构体的内容都拷贝到这N个数组成员中。例如:
1
2
3
4
5
6
7
8
9
10
11
12void *
ngx_http_script_start_code(ngx_pool_t *pool, ngx_array_t **codes, size_t size)
{
if (*codes == NULL) {
*codes = ngx_array_create(pool, 256, 1);
if (*codes == NULL) {
return NULL;
}
}
return ngx_array_push_n(*codes, size);
}HTTP请求到来,脚本指令执行时,每执行完一个脚本指令的ngx_http_script_code_pt方法后,该方法必须主动告知所属指令结构体占用的内存数N,这样从当前指令所在codes数组索引加上N后就是下一条指令。
下图展示了两个请求到来时,解析外部变量的流程:
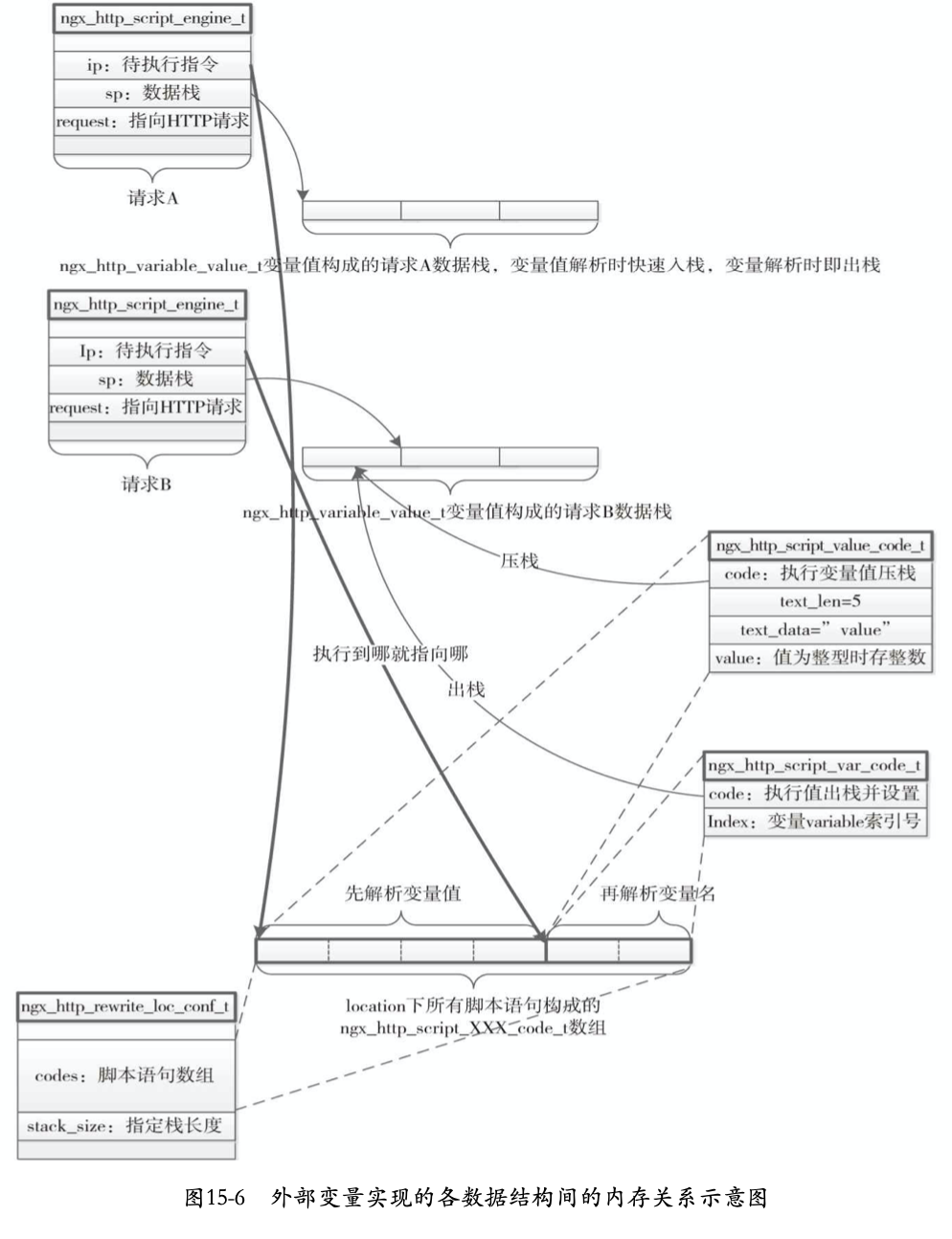
图中以set $variable value作为例子,脚本由右向左解析为ngx_http_script_value_code_t,ngx_http_script_var_code_t。
两个http请求(A和B)同时执行到该脚本,其中A请求正准备执行value指令的ngx_http_script_value_code_t,而B请求已经执行完值的入栈,正要执行ngx_http_script_var_code_t。ngx_http_script_engine_t脚本引擎的sp成员始终指向变量值正要操作的值,而ip成员则始终指向将要执行的下一条指令结构体。
编译set脚本
编译流程如下:

执行流程为:
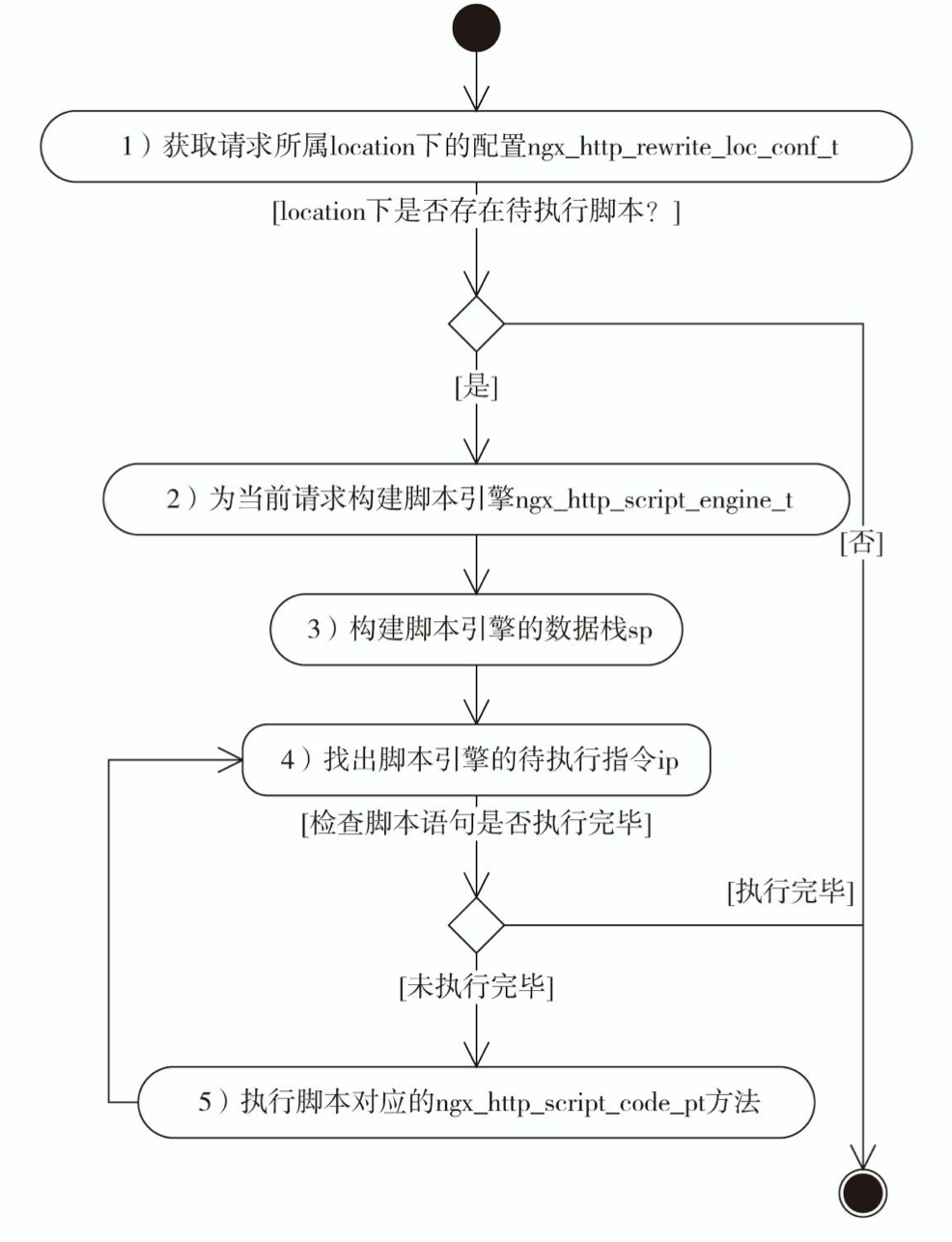
set在ngx_http_rewrite_module模块的配置如下:
1 | { ngx_string("set"), |
其中ngx_http_rewrite_set函数逻辑如下:
1 | static char * |
在第四步中,内部变量的get_handler方法是必须实现的,因此通常都是采用惰性求值,即只有读取到这个变量时才会调用get_handler计算出这个值。然而外部变量是不同的。每一次set都会立即给变量重新赋值,同时读取变量时,因为变量值被索引化的,所有可以直接从请求的variables数组里取到set后的值。这样get_handler似乎是没有用的。然而,可能有某些模块会在set脚本执行前就使用外部变量了,此时外部变量的值是不存在的,即缓存的variables数组里变量是空的。因此这里将get_handler定义为ngx_http_rewrite_var,其功能就是在调用时将变量设置为空值。
1 | ngx_http_variable_value_t ngx_http_variable_null_value = |
对于处理变量值,即value[2]较为复杂。首先定义了两个新的结构:
1 | typedef struct { |
具体代码如下:
1 | static char * |
其中ngx_http_script_compile函数如下:
1 | ngx_int_t |
对于set的脚本变量,ngx_http_script_complex_value_code_t结构的lengths是用来计算变量值所占空间大小,code成员用来在ngx_http_script_engine_t的sp中分配对应的空间。之后使用ngx_http_rewrite_loc_conf_t中的codes成员(一般包含多个)来对分配的内容进行赋值。而后使用ngx_http_rewrite_loc_conf_t中的codes中对变量名的解析方法,来将对应的值赋值给对应的变量。
总体上构建处理函数的顺序为:
- 先将ngx_http_script_complex_value_code_t添加到ngx_http_rewrite_loc_conf_t中的codes成员中。
- 将变量解析的函数的每一部分(一般会含有多个部分)的处理函数(2种处理函数)依次添加到ngx_http_script_complex_value_code_t的lengths成员(计算每一部分生成的值长度)和ngx_http_rewrite_loc_conf_t的codes中(实际执行变量赋值的操作)
- 将变量名解析的函数增加到ngx_http_rewrite_loc_conf_t中的codes成员中。
执行变量构建的顺序为:
- 执行ngx_http_rewrite_loc_conf_t中的codes的ngx_http_script_complex_value_code_t成员的code方法,该方法会调用所有的ngx_http_script_complex_value_code_t中的lengths成员的方法,计算变量值总体占用空间,并在ngx_http_script_engine_t的当前sp中分配对应的空间。
- 接着执行ngx_http_rewrite_loc_conf_t中的codes后续的方法,对分配到sp的空间进行填充,构建完整的变量值。
- 执行变量名的解析函数,将sp中存储的变量值赋值到对应的变量上。
其中ngx_http_script_compile_t中的lengths对应于ngx_http_script_complex_value_code_t中的lengths成员,ngx_http_script_compile_t中的values对应于ngx_http_rewrite_loc_conf_t中的codes成员。
在此基础上再来查看上述代码。首先来看ngx_http_script_complex_value_code_t的code方法,即ngx_http_rewrite_value方法中的
1 | complex->code = ngx_http_script_complex_value_code; |
其中ngx_http_script_complex_value_code方法如下:
1 | void |
再来看一下对不同类型的变量增加相应处理函数的逻辑,这里对于$1类变量较为复杂,目前没有完全理解,暂时先不考虑。这里主要看一下变量名和常量的部分,即如下形式的部分:
1 | set $value "$valueName text" |
其中$valueName部分对应与变量名,” text”对应与常量表达式。其处理函数分别是ngx_http_script_add_var_code和ngx_http_script_add_copy_code。
先来看一下ngx_http_script_add_var_code:
1 | static ngx_int_t |
再看一下ngx_http_script_add_copy_code:
1 | static ngx_int_t |
再来看编译变量名的处理逻辑,对应于ngx_http_rewrite_set函数如下代码段:
1 | // 对于系统内置变量,且支持用户重新使用set设置值的变量来说,会提供set_handler接口,这里使用 |
ngx_http_script_var_handler_code_t结构专门支持内部变量能够被set重新设置,其定义如下:
1 | typedef struct { |
先来看一下函数ngx_http_script_var_set_handler_code,其执行逻辑为:
1 | void |
看一个具有set_handler方法的例子,如agrs:
1 | { ngx_string("args"), |
同样,其取变量的方式是通过offsetof(ngx_http_request_t, args),即r->args里面进行字符串匹配查找数据。
对应不包含set_handler的变量来说,其处理逻辑如下:
1 | void |
变量间merge
在http层的set方法ngx_http_block中的ngx_http_variables_init_vars函数中会对三种变量(hash到变量,索引的变量,前缀变量)进行merge。其方法如下:
1 | ngx_int_t |
举例
对于如下配置,输出为:
1 | location /url { |
对于set $name “$arg_name”;来说,$arg_name作为前缀变量,不可缓存,因此从请求的r->args中获取。这是$name值为test。对于set $args “name=jikui”;来说,由于args允许用户set值,因此其存在set_handler函数。ngx_http_script_var_handler_code_t结构的code方法调用其set_handler函数,设置r->args为"name=jikui"。由于这两步是顺序执行的,因此此时name是test。args是name=jikui。最后的$name = $arg_name”。由于set设置的name变量是可缓存的,因此会直接使用执行set脚本时生成的test值,而对于$arg_name来说,其是不可缓存的变量,因此会再次读取r->args来获取值,因此其值变更为jikui。
共享内存
https://zhuanlan.zhihu.com/p/93684036
ngx_shm_zone_t
其中ngx_shm_zone_t结构如下:
1 | struct ngx_shm_zone_s { |
ngx_shm_t结构
1 | typedef struct { |
锁机制
由于nginx是多进程异步处理,因此很多时候进程间需要使用锁来确保进程安全,进行进程间同步。nginx使用的锁主要涉及三部分内容。方便为文件锁、信号量、原子变量。对于原子变量,可参考如下两篇文章的介绍:
https://www.infoq.cn/article/atomic-operation
https://www.jianshu.com/p/cb7b726e943c
这里主要讲解使用原子变量来构建锁。
相关数据结构
首先来看一下相关数据结构。
ngx_shmtx_t
nginx封装的锁的类。其定义如下:
1 | typedef struct { |
ngx_shmtx_sh_t
由于进程间通讯需要各个进程访问同一个地址,因此该类是nginx封装的一个共享内存创建的锁地址。其由对应的使用方来创建。具体可以参考事件模块构建 accept锁的过程。其结构如下:
1 | typedef struct { |
创建锁
使用ngx_shmtx_create方法来创建锁,其逻辑如下:
1 | ngx_int_t |
销毁锁
使用ngx_shmtx_destroy方法来销毁锁:
1 | void |
即仅在支持信号量,并且成功初始化了信号量时,需要执行一步信号量销毁操作。
非阻塞获取锁
使用ngx_shmtx_trylock函数来非阻塞的获取锁,即如果不能获取锁,则直接返回。
1 | ngx_uint_t |
mtx->lock表示当前未被其他进程占用,但是在执行ngx_atomic_cmp_set的过程前(\mtx->lock == 0后),可能已经被其他进程占用了,因此在原子变量中操作获取锁时,只有当前锁的值依然是0,即在该进程锁住变量前,没有其他进程已经对其进行设置,获取到该锁时,才对其进行赋值,表示当前进程占用该锁。当其他进程希望获取该锁时,由于lock值不为0,返回false。
阻塞式获取锁
使用ngx_shmtx_lock函数来阻塞式获取锁,即直到获取到该锁才返回。
1 |
|
这里ngx_cpu_pause()执行的实际是汇编中pause指令,其会减少CPU的消耗,节省电量。指令的本质功能是:让加锁失败的CPU睡眠大约30个clock,从而使得读操作的频率低很多,流水线重排的代价也会很小。
ngx_sched_yield()执行的是sched_yield()函数,sched_yield()会让出当前线程的CPU占有权,然后把线程放到静态优先队列的尾端,然后一个新的线程会占用CPU。sched_yield()这个函数可以使用另一个级别等于或高于当前线程的线程先运行。如果没有符合条件的线程,那么这个函数将会立刻返回然后继续执行当前线程的程序。 这是其于sleep系列函数的本质区别,而sleep则是等待一定时间后等待CPU的调度,然后去获得CPU资源。
对于阻塞的sem_wait函数,其会阻塞进程。
对于使用信号量时,在将信号量-1后,没有对等待进程数量执行减一操作,该操作在释放信号量时进行。
释放锁
1 | void |
释放信号
在使用信号量时,释放信号后,会释放信号量来唤醒其他等待进程。
1 | static void |
强制释放锁
当某些进程意外退出时,如果其已经获取到了某个锁,这时需要有一个机制能够让其他进程(master)进程来强制释放其所持有的锁。
1 | ngx_uint_t |